Hi everyone,
I am trying to customize the scaled_dot_product_attention() which is called in the multi_head_attention_forward() as part of the MultiheadAttention class. The original scaled_dot_product_attention() is part of torch._C._nn and (in my understanding) comes down to aten::scaled_dot_product_attention in onnx.
When I copy the source code of the MultiheadAttention class, multi_head_attention_forward() function, and use the Python code for scaled_dot_product_attention() (provided by PyTorch in a comment block), the training behavior of my ViT on ImageNet changes drastically. The snippet can be found below:
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0,
is_causal=False, scale=None, enable_gqa=False) -> torch.Tensor:
L, S = query.size(-2), key.size(-2)
scale_factor = 1 / math.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype, device=query.device)
if is_causal:
assert attn_mask is None
temp_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0)
attn_bias.masked_fill_(temp_mask.logical_not(), float("-inf"))
attn_bias.to(query.dtype)
if attn_mask is not None:
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias = attn_mask + attn_bias
if enable_gqa:
key = key.repeat_interleave(query.size(-3)//key.size(-3), -3)
value = value.repeat_interleave(query.size(-3)//value.size(-3), -3)
attn_weight = query @ key.transpose(-2, -1) * scale_factor
attn_weight += attn_bias
attn_weight = torch.softmax(attn_weight, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value
However when I run my training code for the ViT, with the only difference being calling nn.MultiheadAttention() or the copied class with the snippet above for scaled_dot_product_attention(), the training behaviour changes completely. See screenshot below:
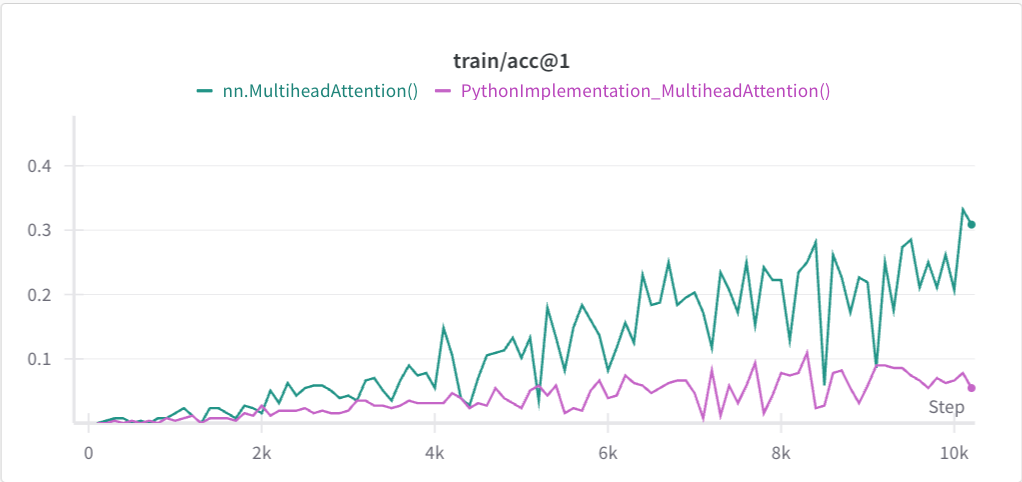
I want to emphasize that I did not do any customization yet and simply copied the commented source code above.
Am I correct to assume that this difference in training behavior can be attributed to using the Python implementation and that if I want to maintain good performance I have to use the optimized implementations? Or is the Python implementation supposed to give the same results but slower?
Subsequently, to customize the attention mechanism, do I have to clone PyTorch, change the .cpp files as discussed here, and build PyTorch from source?
I do not have any experience with this so if there is a PyTorch-based workaround I would love to find out. I looked at jit.trace but what I could find that yields a static computational graph which is fine for inference, but not ideal for training.
Thank you for any help in advance!