I noticed that after the first epoch of training a custom DDP model (1 node, 2 GPUs), two new GPU memory usage entries pop up in nvidia-smi, one for each GPU. A memory usage of around 800 MB is reported for these. Curiously, they have the same PID as the ‘main’ process running on the opposite GPU (see the color-coded screenshot below). Is this expected behavior? It’s the only case of training a model with data parallelism where I noticed it.
I’ve tried using several monitoring tools besides nvidia-smi, e.g. GPUtil.showUtilization(), torch.cuda.memory_allocated(), printing tensors in use, but none of these are descriptive enough for me to pinpoint what exactly is going on.
Any help, suggestions or input would be greatly appreciated!
after the first epoch of training a custom DDP model (1 node, 2 GPUs), two new GPU memory usage entries pop up in nvidia-smi
You mean those two entries was not there during the 1 epoch, and only appears after that? What was executed after the first epoch? How did you initialize DDP? Did you specify device_ids or set CUDA_VISIBLE_DEVICES for the two DDP instances? Looks like both processes are operating on two GPUs. They should have exclusively run on a different GPU.
model = torch.distributed.nn.parallel.DistributedDataParallel(model)
The line above might be the reason. IIUC, torch.cuda.set_device(args.local_rank) only sets the default device, but DDP process can still see two GPUS. By default DDP would try to replicate models on all visible GPUs.
Could you please try use the following to construct DDP?
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[arg.local_rank],
output_device=arg.local_rank)
I might have made a mistake when copying the code from the script to post here In the code that produces the behavior mentioned in the OP, the model is wrapped actually exactly like you propsed, with the addition of the find_unused_parameters argument:
model = torch.nn.parallel.DistributedDataParallel(model,
device_ids=[args.local_rank],
output_device=args.local_rank,
find_unused_parameters=True)
That’s weird. I don’t know why DDP (or sth else) would then try to access a different GPU. Does it work if you set the CUDA_VISIBLE_DEVICES variable to prevent the process from seeing another GPU?
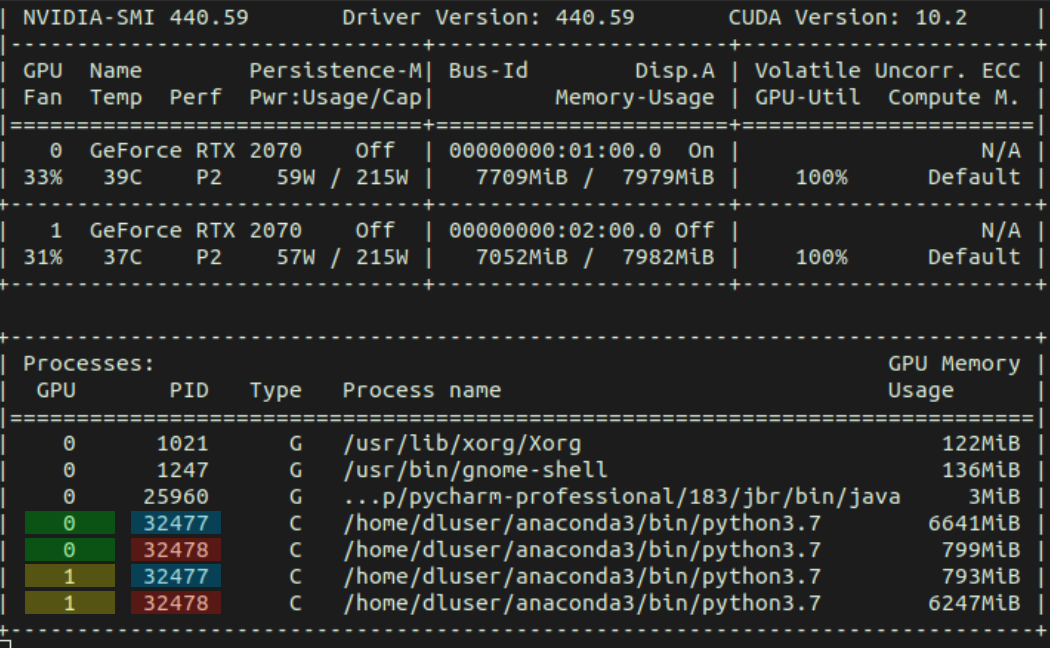
 In the code that produces the behavior mentioned in the OP, the model is wrapped actually exactly like you propsed, with the addition of the
In the code that produces the behavior mentioned in the OP, the model is wrapped actually exactly like you propsed, with the addition of the