Build Pytorch from source.
export CMAKE_PREFIX_PATH=${CONDA_PREFIX:-"$(dirname $(which conda))/../"}
USE_LMDB=ON python setup.py install
The build failed at very beginning (about 3/5xxx) when building protobuf related.
The whole shell exited quietly without visible output.
The output of collect_env.py:
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Fedora Linux 35 (Workstation Edition) (x86_64)
GCC version: (GCC) 11.2.1 20211203 (Red Hat 11.2.1-7)
Clang version: Could not collect
CMake version: version 3.19.6
Libc version: glibc-2.34
Python version: 3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.10-200.fc35.x86_64-x86_64-with-glibc2.34
Is CUDA available: N/A
CUDA runtime version: 11.5.119
GPU models and configuration: GPU 0: Quadro RTX 4000
Nvidia driver version: 495.29.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.2
[conda] blas 1.0 mkl
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.2 py39h20f2e39_0
[conda] numpy-base 1.21.2 py39h79a1101_0
(pytorch) [zf@192 pytorch_1_11]$
Manually complete:
PyTorch version: 1.11.0a0
Is debug build: Y
CUDA used to build PyTorch: 11.5
ROCM used to build PyTorch: N/A
OS: Fedora Linux 35 (Workstation Edition) (x86_64)
GCC version: (GCC) 11.2.1 20211203 (Red Hat 11.2.1-7)
Clang version: Could not collect
CMake version: version 3.19.6
Libc version: glibc-2.34
Python version: 3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.10-200.fc35.x86_64-x86_64-with-glibc2.34
Is CUDA available: Y
CUDA runtime version: 11.5.119
GPU models and configuration: GPU 0: Quadro RTX 4000
Nvidia driver version: 495.29.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.2
[conda] blas 1.0 mkl
[conda] magma-cuda110 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.2 py39h20f2e39_0
[conda] numpy-base 1.21.2 py39h79a1101_0
(pytorch) [zf@192 pytorch_1_11]$
I’ve had nvcc installed but don’t know if it worked:
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Thu_Nov_18_09:45:30_PST_2021
Cuda compilation tools, release 11.5, V11.5.119
Build cuda_11.5.r11.5/compiler.30672275_0
It may be caused by memory/cpu shortage:
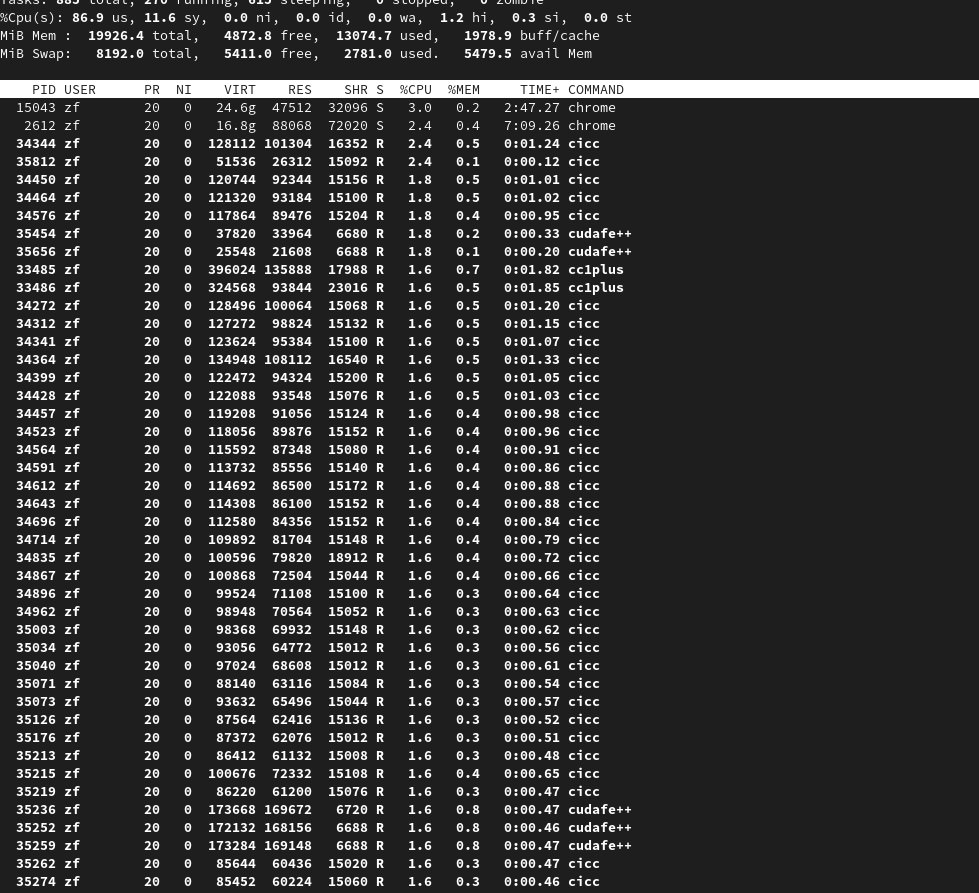
Would you please help? Thank you.