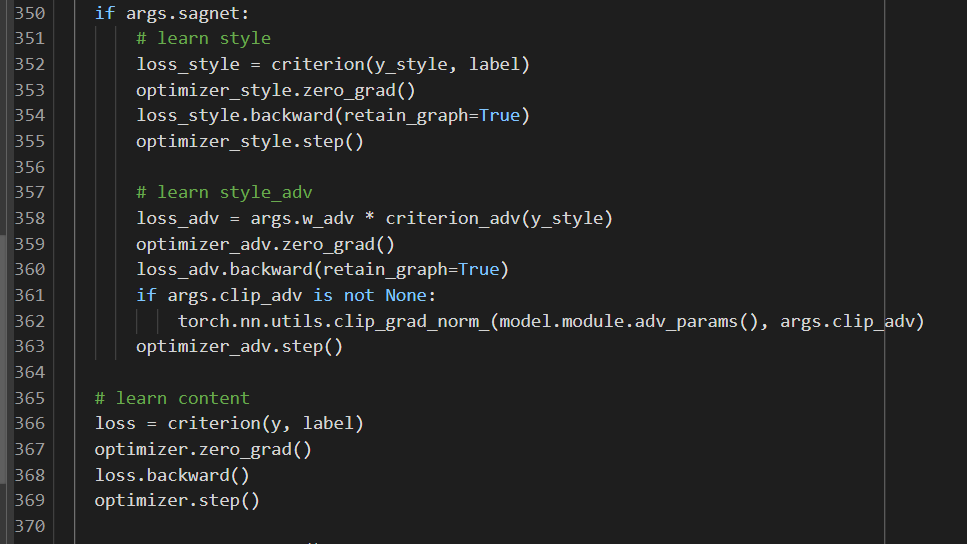
Hi guys . I met the problem with loss.backward() as you can see here
File “train.py”, line 360, in train
loss_adv.backward(retain_graph=True)
File “/usr/local/lib/python3.7/dist-packages/torch/_tensor.py”, line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File “/usr/local/lib/python3.7/dist-packages/torch/autograd/init.py”, line 175, in backward
allow_unreachable=True, accumulate_grad=True) # Calls into the C++ engine to run the backward pass
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [512, 7]], which is output 0 of AsStridedBackward0, is at version 2; expected version 1 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
When I don’t use retain_graph=True I meet this problem
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.