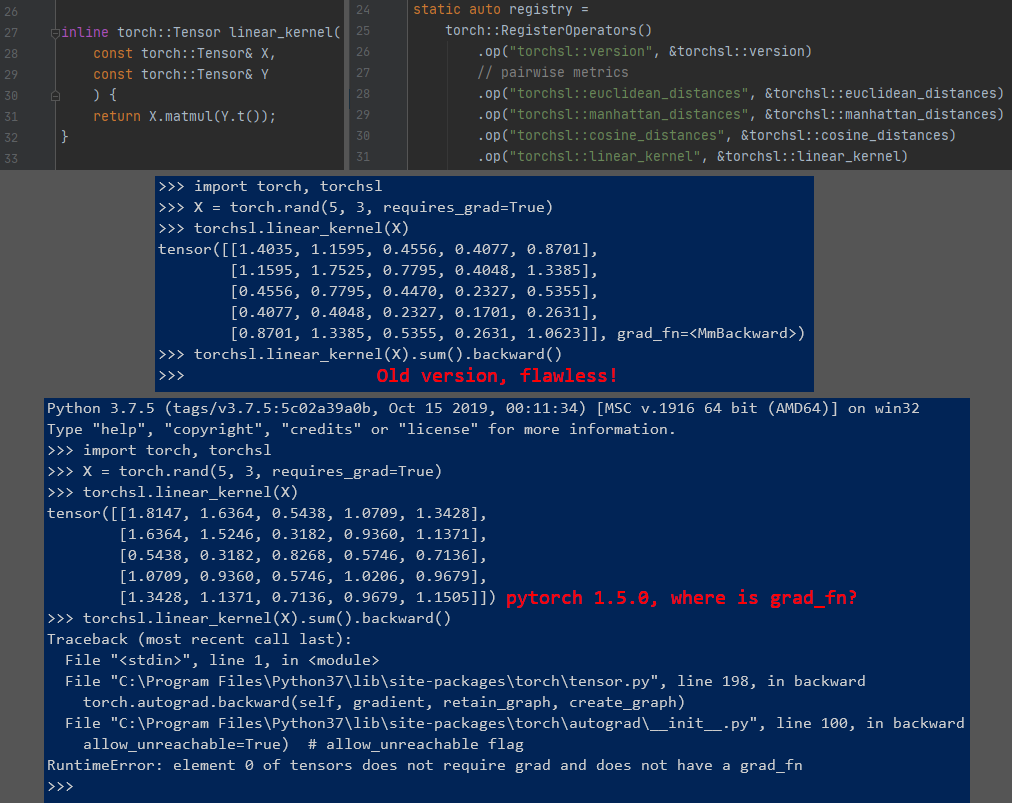
In pytorch 1.4.0 (and probably every previous versions), I could simply rewrite my python code in C++, put it inside a vanilla function, and call it from python with Pybind11 or with torch script’s RegisterOperators. The autograd works perfectly while giving the foreign code an edge over pure python in terms of performance.
However, pytorch 1.5.0 surprised me when it eliminate every gradient of input tensor. Now am I supposed to manually expand and write backward pass on my own whenever I touch C++ side ![]() ? Anyone know how to work around this please help?
? Anyone know how to work around this please help?
The pic is an example of a very simple function from the project i’m working on, obviously there is no need for grad checking here.
I posted an issue for this here: https://github.com/pytorch/pytorch/issues/37306