My environment is
- OS: Ubuntu 18.04
- GPU: RTX3090
- CUDA: CUDA11.2
- Pytorch 1.8.0_with_CUDA11.1 stable
from torchvision.models.detection import fasterrcnn_resnet50_fpn
box_model = fasterrcnn_resnet50_fpn(pretrained=True, progress=False).cuda()
xs = torch.rand(2, 3, 1080, 1920, dtype=torch.float32).cuda()
ys = [
{
"labels": torch.tensor([1], dtype=torch.int64).cuda(),
"boxes": torch.tensor([[956.0000, 316.3117, 1134.0000, 838.8275]],
dtype=torch.float32).cuda(),
},
{
"labels": torch.tensor([1], dtype=torch.int64).cuda(),
"boxes": torch.tensor([[956.0000, 316.3117, 1134.0000, 838.8275]],
dtype=torch.float32).cuda(),
},
]
box_model(xs, ys)
It occurs error like this.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-13-7f582a050256> in <module>
----> 1 box_model(xs, ys)
~/anaconda3/envs/torch/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~/anaconda3/envs/torch/lib/python3.7/site-packages/torchvision/models/detection/generalized_rcnn.py in forward(self, images, targets)
95 if isinstance(features, torch.Tensor):
96 features = OrderedDict([('0', features)])
---> 97 proposals, proposal_losses = self.rpn(images, features, targets)
98 detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
99 detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
~/anaconda3/envs/torch/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
~/anaconda3/envs/torch/lib/python3.7/site-packages/torchvision/models/detection/rpn.py in forward(self, images, features, targets)
363 regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
364 loss_objectness, loss_rpn_box_reg = self.compute_loss(
--> 365 objectness, pred_bbox_deltas, labels, regression_targets)
366 losses = {
367 "loss_objectness": loss_objectness,
~/anaconda3/envs/torch/lib/python3.7/site-packages/torchvision/models/detection/rpn.py in compute_loss(self, objectness, pred_bbox_deltas, labels, regression_targets)
294 """
295
--> 296 sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
297 sampled_pos_inds = torch.where(torch.cat(sampled_pos_inds, dim=0))[0]
298 sampled_neg_inds = torch.where(torch.cat(sampled_neg_inds, dim=0))[0]
~/anaconda3/envs/torch/lib/python3.7/site-packages/torchvision/models/detection/_utils.py in __call__(self, matched_idxs)
55 # randomly select positive and negative examples
56 perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
---> 57 perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
58
59 pos_idx_per_image = positive[perm1]
RuntimeError: radix_sort: failed on 1st step: cudaErrorInvalidDevice: invalid device ordinal
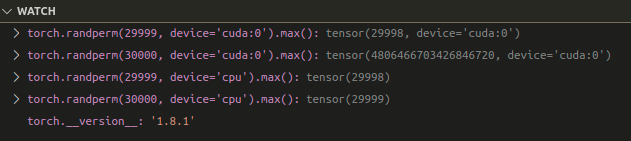
When I try this code on CPU, it works fine.
After that, I reinstalled Pytorch 1.7.1_with_CUDA11.0 stable, it works fine too.