Hey there so i’m using Tensorboard to validate / view my data. I am using a standard NN with FashionMNIST / MNIST Dataset.
First, my code:
import math
import torch
import torch.nn as nn
import numpy as np
import os
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
learning_rate = 0.01
BATCH_SIZE = 64
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda
from torch.utils.tensorboard import SummaryWriter
import tensorboard
writer = SummaryWriter()
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
model1 = NeuralNetwork()
loss_fn = nn.CrossEntropyLoss()
loss_fn1 = nn.CrossEntropyLoss()
def get_w_old(model):
return [torch.zeros_like(p.data) for p in model.parameters()]
def update_function(param, grad, loss, learning_rate, momentum):
return param - learning_rate * grad
loss_old = None
loss_list = []
def train_loop1(dataloader, model1, loss_fn1, optimizer, epoch):
size = len(dataloader.dataset)
global running_loss
for batch, (X, y) in enumerate(dataloader):
pred = model1(X)
optimizer.zero_grad()
loss = loss_fn1(pred, y)
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
writer.add_scalar("Loss/train", loss, epoch)
print(f"loss: {loss: >7f} [{current: >5d}/{size: >5d}]")
def test_loop(dataloader, model, loss_fn, epoch):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, correct = 0, 0
with torch.no_grad():
for X,y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
writer.add_scalar('Avg. Loss', test_loss, epoch)
writer.add_scalar('Accuracy', 100*correct, epoch)
writer.add_scalar('Total correct', 100*correct / size, epoch)
epochs = 25
# Ultra ELITE optimizer
for t in range(epochs):
print("training with SGD and Momentum set to 0.8")
print(f"Epoch {t + 1}\n-------------------------------")
#optimizer = torch.optim.SGD(model1.parameters(), lr=0.1)
optimizer = torch.optim.Adam(model1.parameters(),lr=0.001,betas=(0.9,0.999),eps=1e-08,weight_decay=0,amsgrad=False)
train_loop1(train_dataloader, model1, loss_fn1, optimizer, t)
test_loop(test_dataloader, model1, loss_fn1, t)
print("Done!")
writer.flush()
writer.close()
It is a simplified version, as i have some custom implementations in my code as well, however, the code i’ve posted is exactly what i use to determine the perfomance of any optimizer that is already inside PyTorch optim library (i use these to do comparisons).
Now, taking a look at these screenshots, ADAM’s perfomance( orange graph, lr=0.001, beta= 0.9, 0.999, weight_decay = 0, amsgrad=False) is sometimes worse and has also some crazy spikes in Avg. Loss, while SGD with Momentum (Purple Graph, lr=0.01, momentum=0.8)don’t:

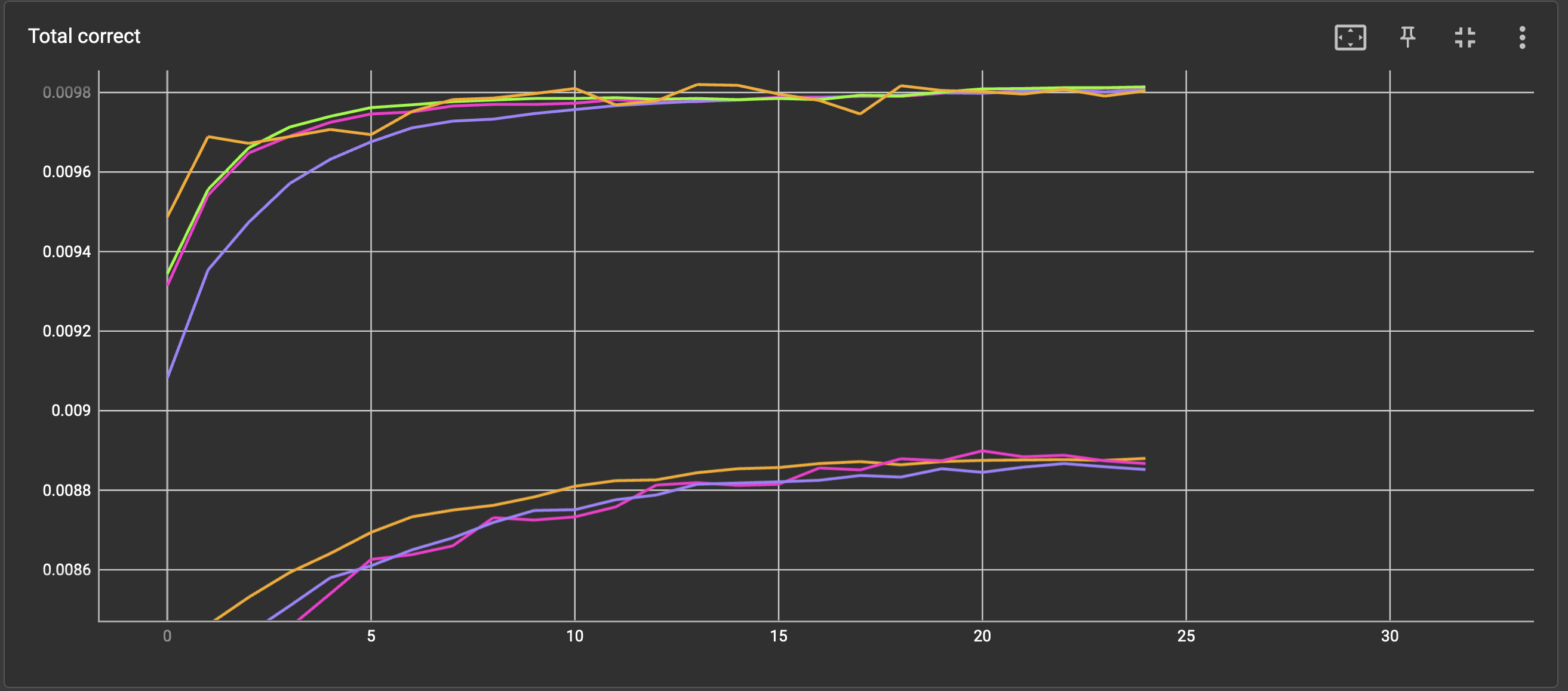
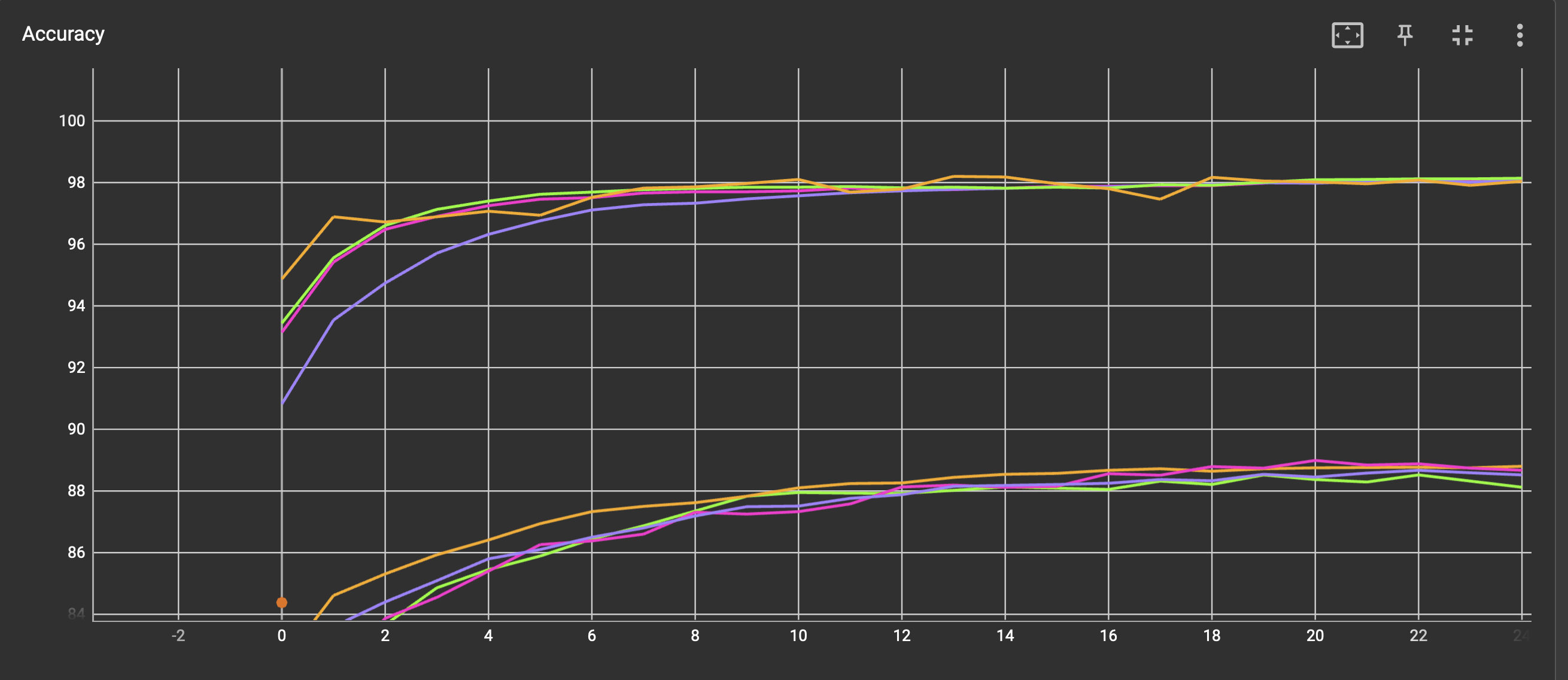
Given my code: Do i measure something wrong or is this normal? If so, why is the Avg. Loss of ADAM so much worse compared to SGD with and without Momentum for the MNIST Dataset?
Thanks in advance!