Dear all I have some question…
I try to do some transfer learning using resnet50. I use kubernets machine and use one gpu and all the tensor are redirected to device cuda.
...code...
criterion = nn.CrossEntropyLoss(weight=weights)
model.train() # Set model to training mode
global_i = 0
losses_tr = []
losses_ts = []
last_loss_test = -1
iteration = 0
start_time = time.time()
for epoch in range(EPOCHS):
if epoch % 10 == 0: # save checkpoint
torch.save(
model.state_dict(),
f"{EXPERIMENT_DIR}/checkpoint.pth",
)
for j, data in enumerate(loader_train):
global_i += 1
if j % 10 == 0:
print(time.time() - start_time)
start_time = time.time()
optimizer.zero_grad()
images_tr = data["data"].to(device)
labels_tr = torch.LongTensor(data["label"]).to(device)
outputs_tr = model(images_tr).to(device)
# backward
loss = criterion(outputs_tr, labels_tr)
loss.backward()
optimizer.step()
# check test set
if j % int(len(loader_train) / 2) == 0 and j != 0:
model.eval()
with torch.no_grad():
losses_sum = 0
num_samples_test = 0
for data_test in loader_test:
images_ts = data_test["data"].to(device)
labels_ts = torch.LongTensor(data["label"]).to(device)
outputs_ts = model.forward(images_ts)
loss_test_sum = criterion(outputs_ts, labels_ts).item()
losses_sum += loss_test_sum
num_samples_test += 1
loss_test_avg = losses_sum / num_samples_test
losses_tr.append(loss.item())
losses_ts.append(loss_test_avg)
del images_ts, labels_ts
iteration += 1
del images_tr, labels_tr
gc.collect()
model.train()
# torch.backends.cuda.cufft_plan_cache.clear()
the device are gpu but they seme use only a small part . I have image 64x64x64 with bacth size of 4 or 8 or 12…
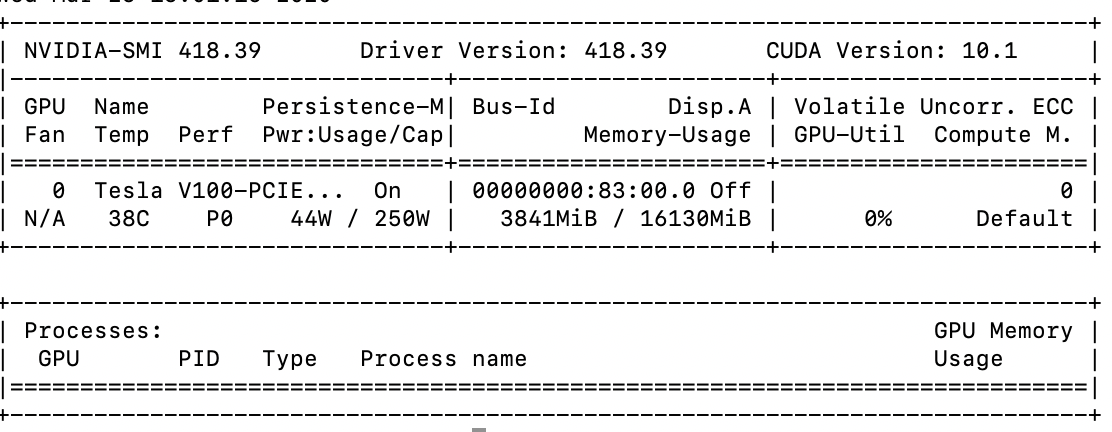
thanks in advance for any help
