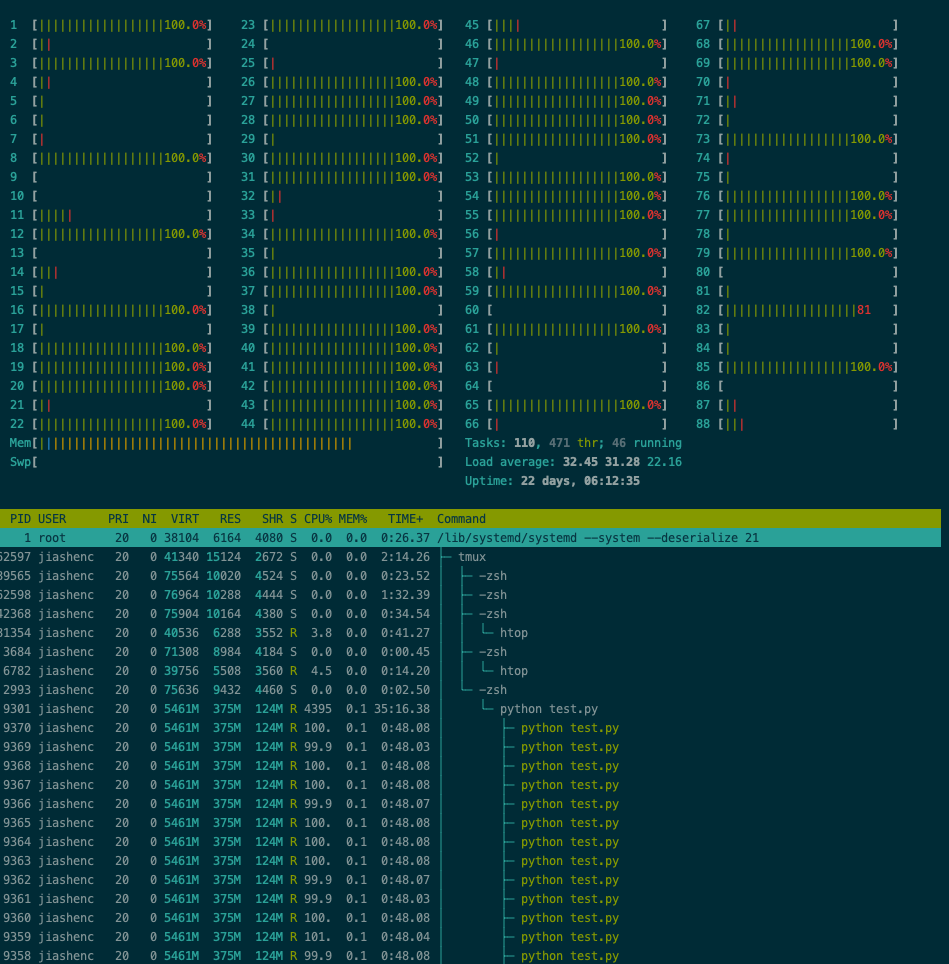
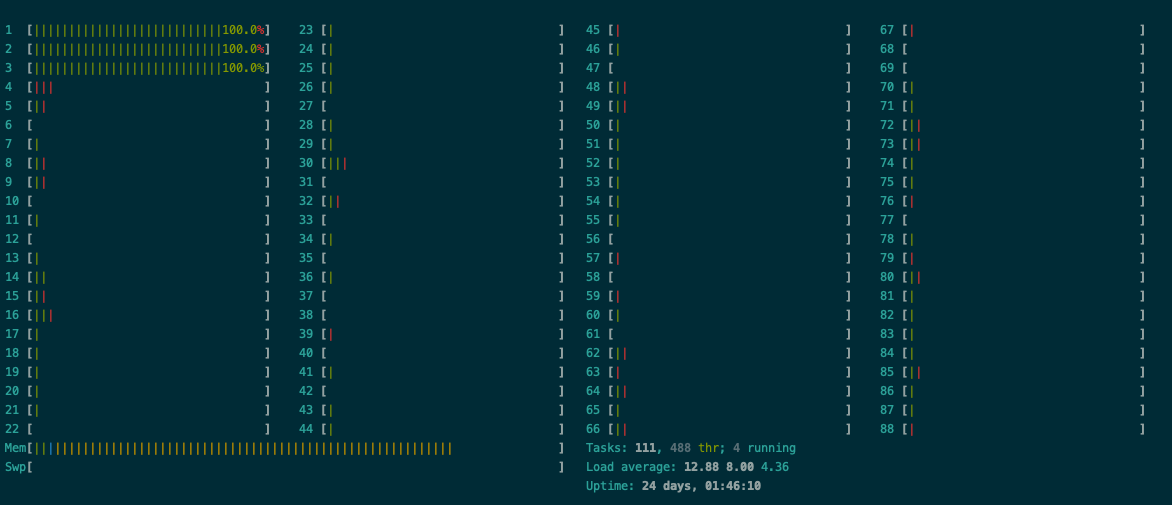
I am running a simple while loop for inference on CPU. I want the inference to run only on 1 CPU, but it seems like PyTorch changes the process affinity. I can see from htop that jobs are being scheduled on multiple CPUs that I do not expect.
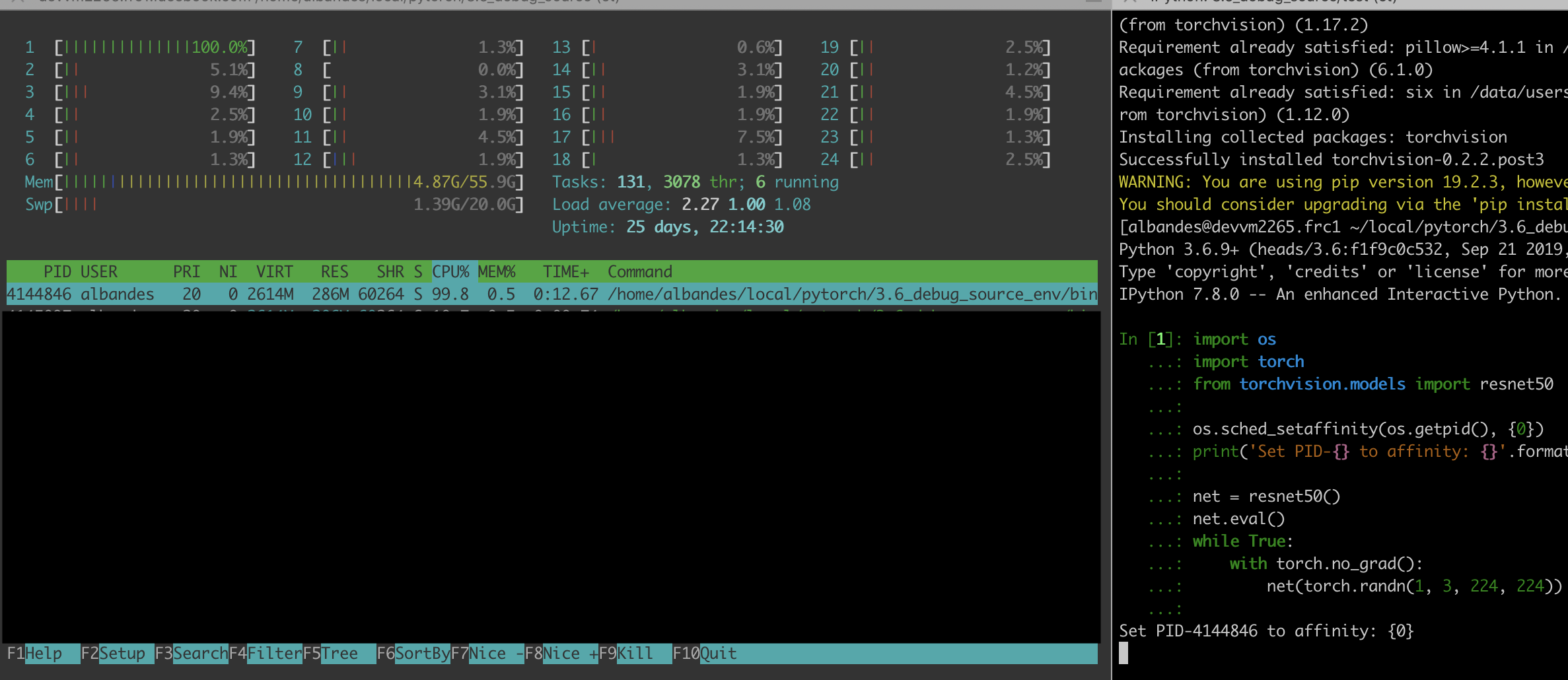
My python program.
import os
import torch
from torchvision.models import resnet50
os.sched_setaffinity(os.getpid(), {0})
print('Set PID-{} to affinity: {}'.format(os.getpid(), os.sched_getaffinity(os.getpid())))
net = resnet50()
net.eval()
while True:
with torch.no_grad():
net(torch.randn(1, 3, 224, 224))
Output from affinity setting and my htop monitoring.
import os
import numpy as np
os.sched_setaffinity(os.getpid(), {0, 1, 2})
print('Set PID-{} to affinity: {}'.format(os.getpid(),
os.sched_getaffinity(os.getpid())))
while True:
a = np.random.random_sample([100, 100])
b = np.random.random_sample([100, 100])
c = np.dot(a, b)
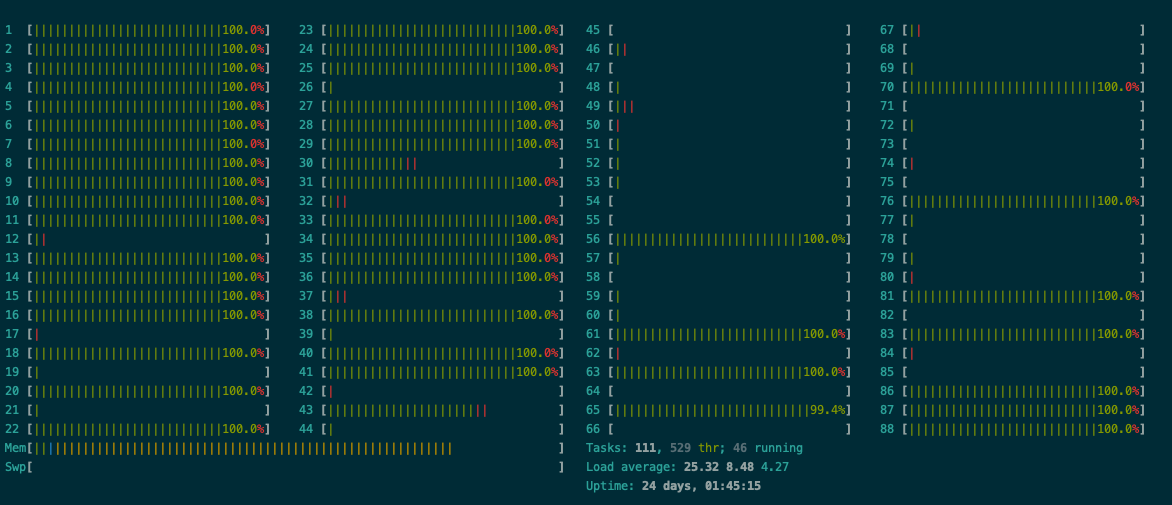
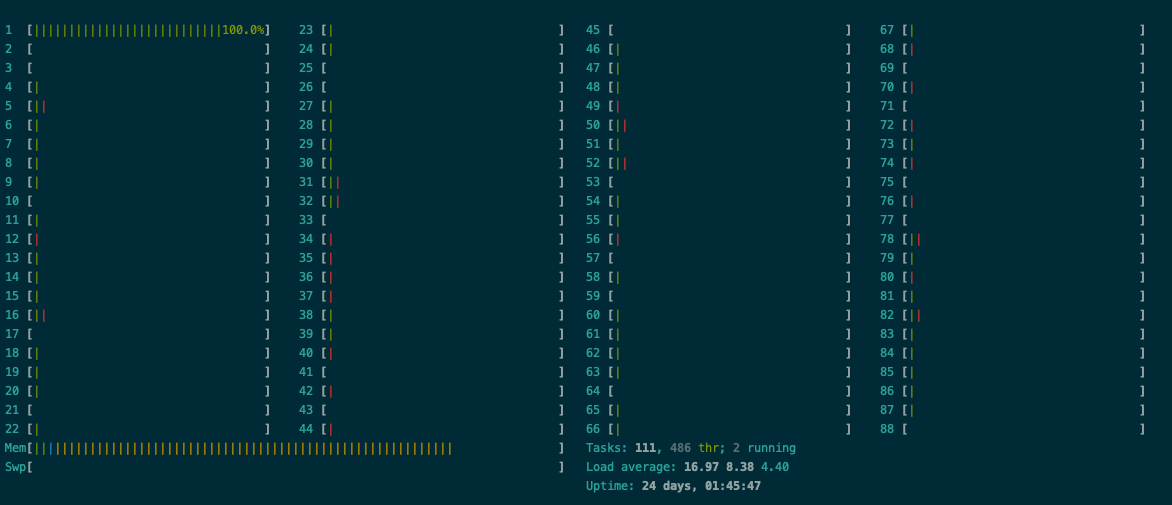
Interestingly, that does not work on my machine for numpy, and uses multiple cores and changes
I guess some BLAS libraries might not be following this.
You can try running different ops in the while loop. Just the random numbers vs only the dot for example.


 So maybe a similar MKL flag is needed?
So maybe a similar MKL flag is needed?