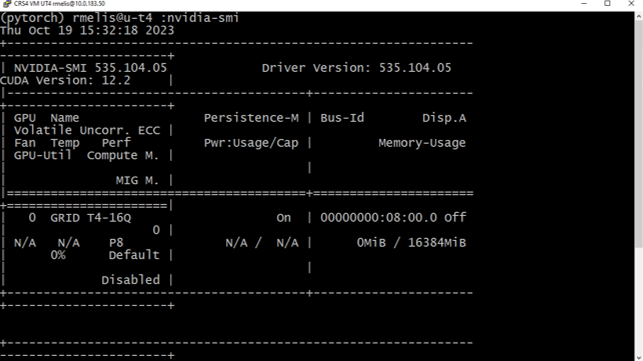
First, the as is cuda version not load the dynamic library libcudnn.so.8. When I tried to install previous pythorch and associated cuda versions the torch library give me other errors.
Can you suggest me a proper associations between torch and my nvidia workstation?..Thanks in advance!
Driver 535.104.05 is compatible with every stable and nightly binary we are building.
I don’t understand this statement since the PyTorch binaries ship with their own CUDA dependencies (including cuDNN and NCCL etc.) and load these. Your locally installed CUDA toolkit won’t be used so if you want to use a custom setup you should build PyTorch from source.
Sorry for unclearity in my question ( I’m still a novice with torch…), I’ll try to explain now better :
The error appears only when I run the training in the previous mentioned code ( the necessary libraries were all correctly loaded). Here the full msn :
“Could not load library libcudnn_cnn_train.so.8. Error: /usr/local/cuda/lib64/libcudnn_cnn_train.so.8: undefined symbol: _ZN5cudnn3cnn34layerNormFwd_execute_internal_implERKNS_7backend11VariantPackEP11CUstream_stRNS0_18LayerNormFwdParamsERKNS1_20NormForwardOperationEmb, version libcudnn_cnn_infer.so.8”
In particular, I dont’ understand about this error in particular ( maybe it come from the code?)
" undefined symbol: _ZN5cudnn3cnn34layerNormFwd_execute_internal_implERKNS_7backend11VariantPackEP11CUstream_stRNS0_18LayerNormFwdParamsERKNS1_20NormForwardOperationEmb"
The system path points to a cuDNN installation in /usr so either remove this cuDNN version completely and let PyTorch use its own cuDNN libs or remove this path from LD_LIBRARY_PATH as a workaround.