Hi everyone, I need help.
For a class assignment, I have to reimplement a paper called “3D Convolutional Neural Networks for Human Action Recognition”. The paper proposed this convolutional network
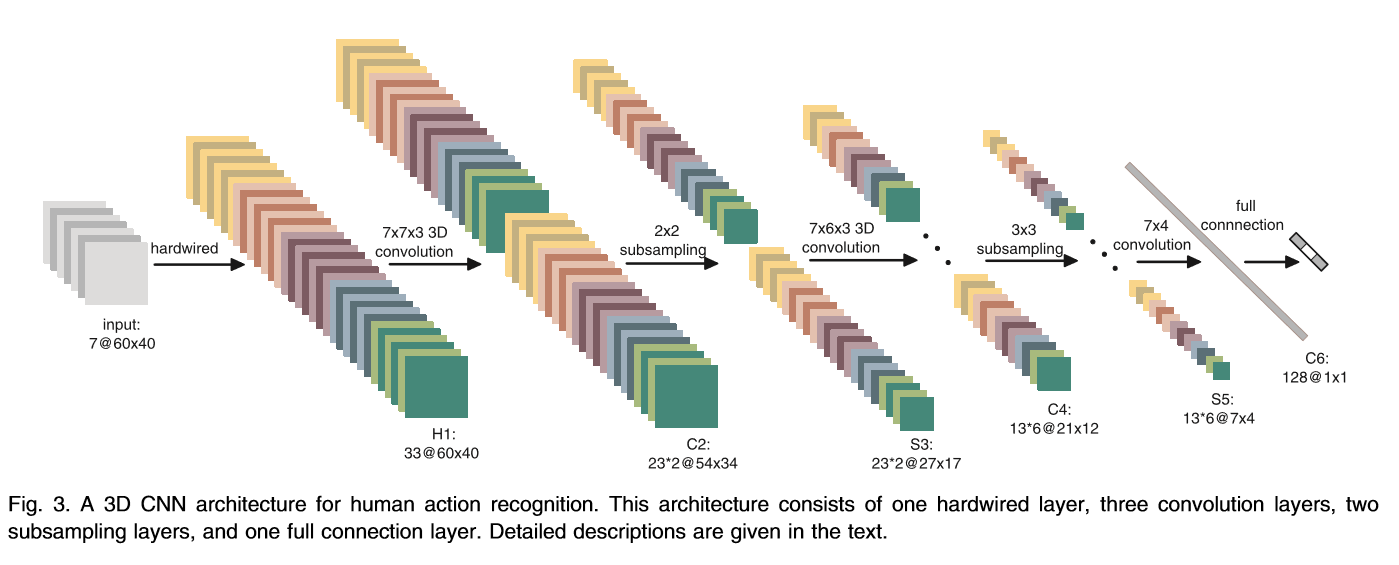
Currently, I’m stuck on the hardwired layers which are composed of 5 distinct channels: gray, gradient-x, gradient-y, optflow-x, optflow-y. The gray channel contains the gray pixel values of the seven input frames. The gradient-x and gradient-y are obtained by calculating on the horz and vertical directions, respectively, on each seven input frames. Finally, the optical flow x and optical flow y channels contain the optical flow fields along the horizontal and vertical directions, computed from adjacent input frames.
grey, gradient-y, and gradient-x has the dimension of (7,60,40) (DxHxW) while opt-x and y have the dimension of (6,60,40). I computed gradient using np.gradient() and computed optical flow using cv2.calcOpticalFlowFarneback(). In order to push everything into CUDA, I computed this in my DataLoader; However, due to the size mismatch, I can’t concatenate them into a single cube. Do you guys have any suggestion?