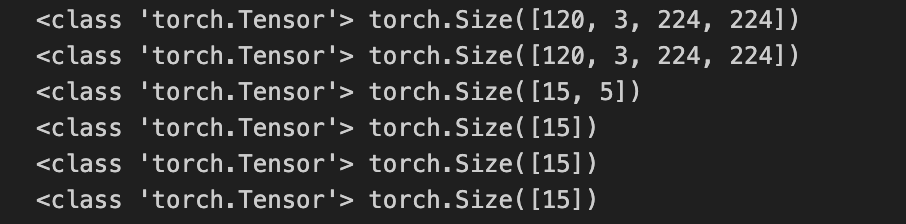
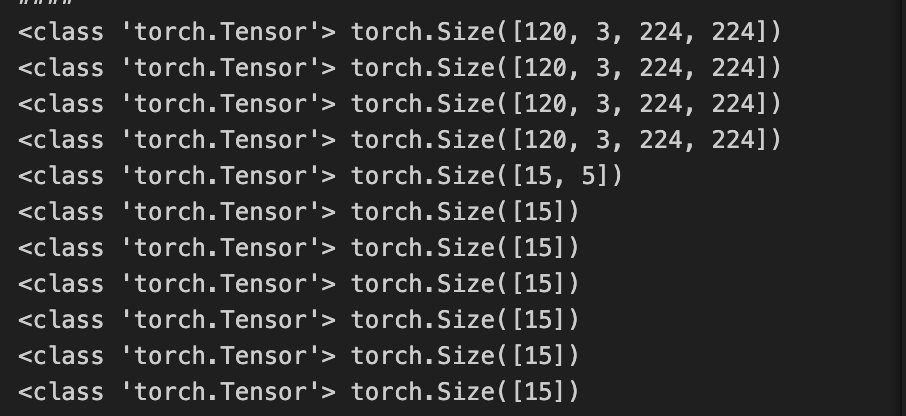
I am training a model on a few shot problem. However my gpu consumption keep increasing after every iteration. At each iteration, I use only 1 few shot task. I have read other posts on this gpu mem increase issue and implement the suggestions including
- use total_loss += lose.item() instead of total_loss += loss.
- delete variable loss
- use torch.cuda.empty_cache()
However, it still doesn’t work. I would appreciate your help.
Below is my train loop
def compute_loss(cfg, input, output):
loss = F.cross_entropy(output['logits'], input['labels'])
return loss
def train_epoch(
cfg,
train_loader,
val_loader,
model,
optimizer,
scheduler,
):
"""
Perform the video training for one epoch.
Args:
train_loader (loader): video training loader.
model (model): the video model to train.
model_ema (model): the ema model to update.
optimizer (optim): the optimizer to perform optimization on the model's
parameters.
train_meter (TrainMeter): training meters to log the training performance.
cur_epoch (int): current epoch of training.
cfg (Config): The global config object.
"""
# Enable train mode.
model.to(DEVICE)
model.train()
if cfg.TRAIN.type == 'iter':
num_iter = cfg.TRAIN.NUM_TRAIN_ITER
elif cfg.TRAIN.type == 'meta':
num_iter = cfg.TRAIN.NUM_TRAIN_TASKS
loader_iter = iter(itertools.cycle(train_loader))
running_acc = 0
running_loss = 0
log_interval = cfg.STEP_PER_LOG
val_interval = cfg.TRAIN.VAL_FRE_ITER
assert val_interval % log_interval == 0
gradient_accumulation_steps = cfg.GRADIENT_ACCUMULATION_STEPS
last_checkpoint_path = None
keep_num_best = cfg.num_best_checkpoint if hasattr(cfg, "num_best_checkpoint") else 3
ckpt_saver = CheckpointSaver(keep_num_best=keep_num_best)
# warm up
input = next(loader_iter)
input = squeeze(input, DEVICE)
input["split"] = "train"
output = model(input)
# debug
with open("debug.txt", 'w') as f:
pass
for cur_iter in tqdm(range(num_iter)):
wandb_log = {}
input = next(loader_iter)
input = squeeze(input, DEVICE)
input["split"] = "train"
with profiler.profile(with_stack=True, profile_memory=True) as prof:
output = model(input)
with open("debug.txt", 'a') as f:
f.write(prof.key_averages().table(sort_by="cpu_time_total"))
f.write("\n")
loss = compute_loss(cfg, input, output)
loss.backward()
# acc = compute_accuracy(cfg, input, output)
# running_acc += acc.item()
running_loss += loss.item()
del loss
if (cur_iter + 1) % gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
scheduler.step()
# evaluate
if (cur_iter + 1) % val_interval == 0:
with torch.no_grad():
res = inductive_evaluate(
cfg, model, val_loader, cfg.TRAIN.NUM_VAL_TASKS, "val"
)
assert isinstance(res, dict)
wandb_log.update({"val_acc": res["acc"], "val_loss": res["loss"]})
stat = {"iter": cur_iter}
ckpt_saver(
res["acc"],
cfg.OUTPUT_DIR + f"/best_{cur_iter+1:05}_acc{res['acc']:.3f}.pt",
partial(
save_checkpoint,
model=model,
optimizer=optimizer,
scheduler=scheduler,
stat=stat,
),
)
remove_file(last_checkpoint_path)
last_checkpoint_path = (
cfg.OUTPUT_DIR + f"/last_{cur_iter+1:05}_acc{res['acc']:.3f}.pt"
)
save_checkpoint(
model, optimizer, scheduler, stat=stat, save_path=last_checkpoint_path
)
model.train()
if (cur_iter + 1) % log_interval == 0:
lr = optimizer.param_groups[0]["lr"]
wandb_log["lr"] = lr
wandb_log.update(
{
f"train_loss_{log_interval}": running_loss / log_interval,
f"train_acc_{log_interval}": running_acc / log_interval,
}
)
running_loss = 0
running_acc = 0
wandb.log(wandb_log)
# del loss, acc, output, input
# torch.cuda.empty_cache()
return {"best_checkpoint": ckpt_saver.get_best_checkpoint_path()}