It says CUDA-based C++ code is slower than custom CUDA kernel. The two method both run codes on cuda device in c++ with the same operator. Why there is a speed gap between them?
Thank you.
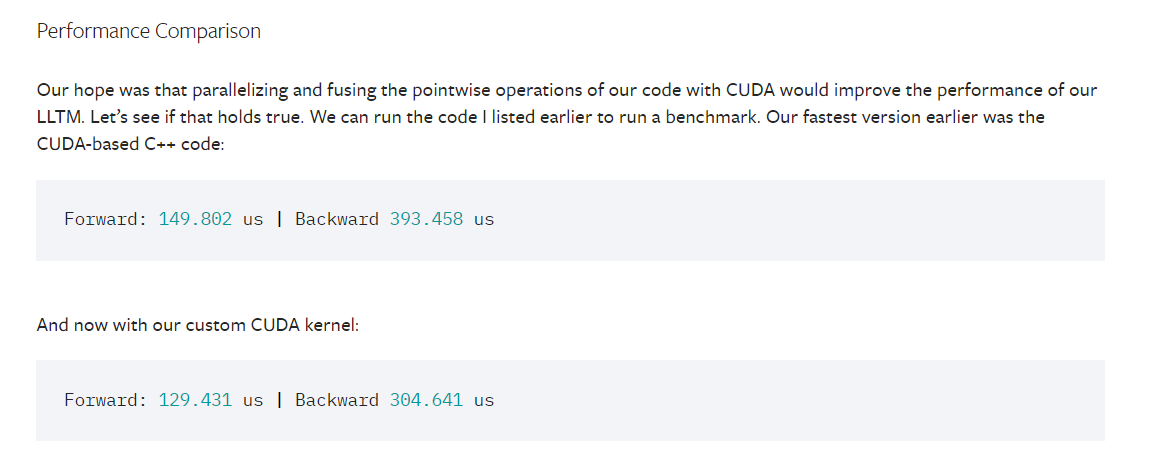
As described in the tutorial, the next step after writing the extension is to write a custom CUDA kernel and reduce the kernel launch overheads:
A definite method of speeding things up is therefore to rewrite parts in C++ (or CUDA) and fuse particular groups of operations. Fusing means combining the implementations of many functions into a single functions, which profits from fewer kernel launches as well as other optimizations we can perform with increased visibility of the global flow of data.
For the LLTM, this has the prospect of being particularly effective, as there are a large number of pointwise operations in sequence, that can all be fused and parallelized in a single CUDA kernel.