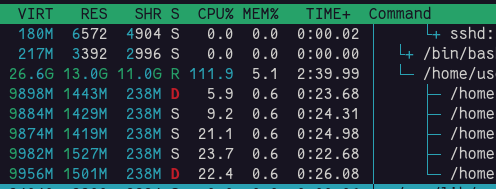
Hi, I noticed that while training a PyTorch model the subprocesses that are started by the dataloader workers are accumulating memory over time while loading new batches and it seems this memory is never released, ultimately resulting in a “dataloader worker does not have sufficient shared memory” error. Could this be a memory leak or is this a known “bug”.
The PyTorch version i am using is 2.0 for CUDA 11.7 in case this information helps.
Yes I already checked this issue, unfortunately this didn’t help. What I notice is that even if I set num_workers = 0 the shared memory of the process that runs the script keeps increasing until the shared memory error appears.
Ok there seems to be a bug when runnning a whole script under a torch.inference_mode() context. Using inference mode only on model calls works fine and the leak is gone. I’ll try to make a minimal reproducible example.
+1 This solved my issue. Seems like anytime you don’t use a copy of the tensor returned by the loader, it defaults to writing it to shared memory (without garbage collecting it as needed)