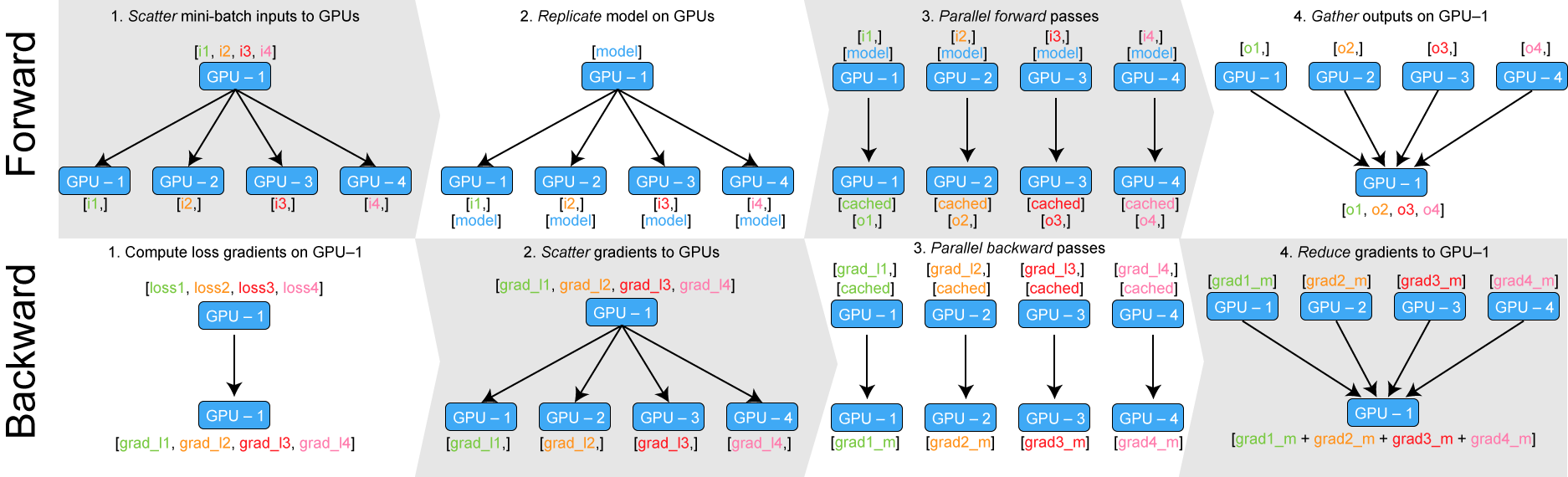
nn.DataParallel is easy to use when we just have neural network weights.
- What if we have an arbitrary preprocessing (non-differentiable) function in our module? nn.DataParallel does not seem to work well on arbitrary Pytorch tensor functions; at the very least it doesn’t understand how to allocate the tensors dynamically to the right GPU.
For example, I have this normalization code as the preprocessing for my module:
def normalize(self, v): ... return torch.clamp((v.to(torch.cuda.current_device()) - mean.to(torch.cuda.current_device())) / std, -clip_range, clip_range)
I get this error:
RuntimeError: binary_op(): expected both inputs to be on same device, but input a is on cuda:1 and input b is on cuda:0
I get the above error with or without the “to(torch.cuda.current_device())”
-
What if we spawn weights outside of the init function?
E.g. torch.zeros(…) usually gives a similar “Input a is on cuda:1 and input b is on cuda:0” error. I fixed in these cases with “to(torch.cuda.current_device())” but not sure if there’s a silent error affecting the training speed -
How do we actually check that the tensors are being properly distributed across GPUs and we didn’t break the speed somewhere by moving from GPU -> CPU accidentally?