Hi everyone, I’m new to PyTorch so this may be a dumb question.
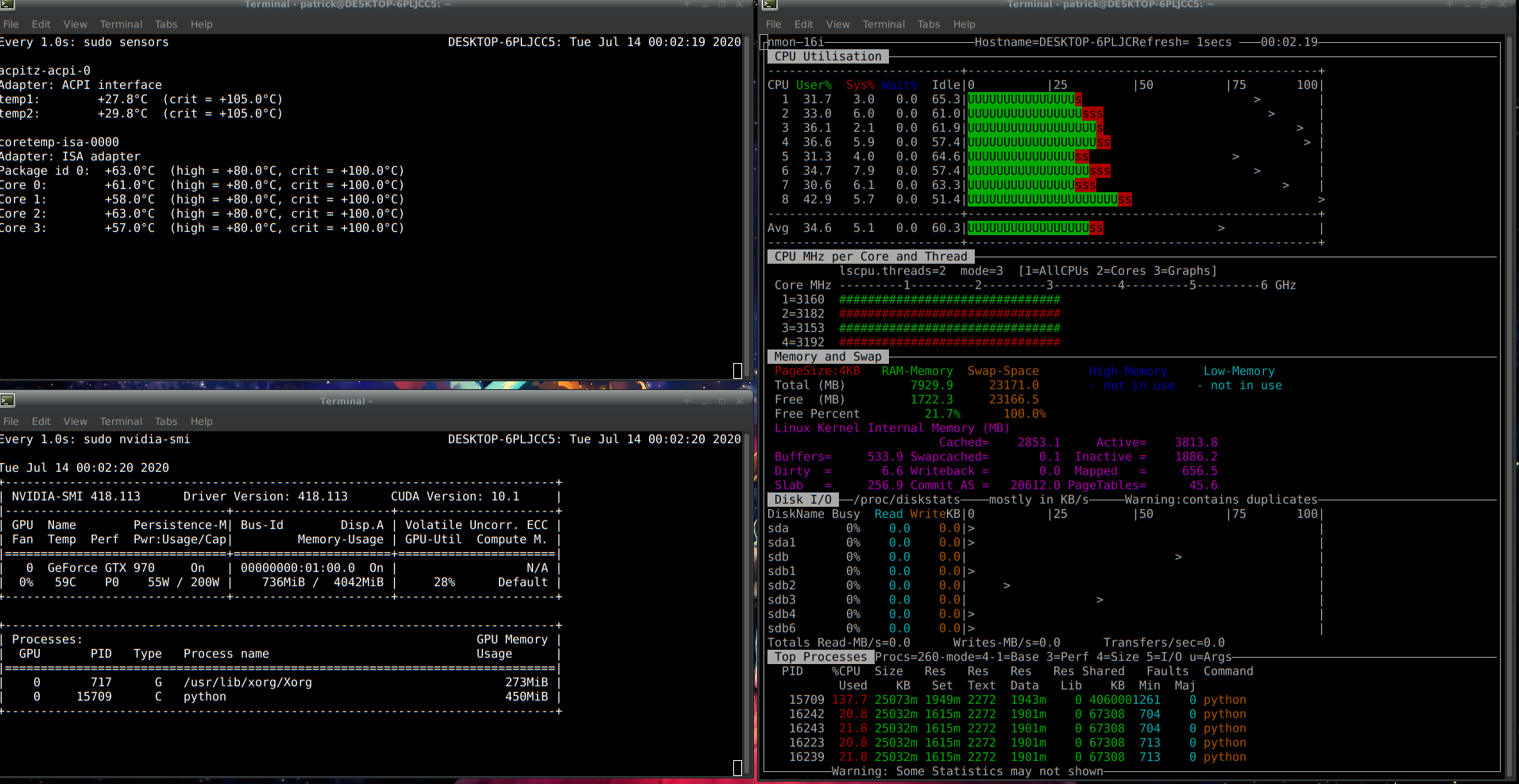
I’m running this program on an i7 4790, 8gb ram and 970 4gb with Debian 10.
As you can see in the screenshot, it seems to not use all the power he could.
Here is the code I wrote (just the relevant part)
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
batch_size = 10
learning_rate = 0.06
epochs = 30
momentum = 0.00
lr_step_size = 5
lr_gamma = 0.3
hidden_neurons1 = 600
hidden_neurons2 = 600
activation = nn.LeakyReLU()
device = "cuda:0"
num_workers = 8
pretrained = False
class DeepNet(nn.Module):
def __init__(self, input_units, hidden_units1,hidden_units2, output_units):
super(DeepNet, self).__init__()
self.fc1 = nn.Linear(input_units, hidden_units1)
self.fc2 = nn.Linear(hidden_units1, hidden_units2)
self.fc3 = nn.Linear(hidden_units2, output_units)
self.act = activation
nn.init.xavier_normal_(self.fc1.weight)
nn.init.xavier_normal_(self.fc2.weight)
nn.init.xavier_normal_(self.fc3.weight)
def forward(self, x):
x = self.act(self.fc1(x))
x = self.act(self.fc2(x))
x = self.fc3(x)
return x
net = DeepNet(784, hidden_neurons1, hidden_neurons2, 10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=learning_rate, momentum=momentum)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=lr_step_size, gamma=lr_gamma)
experiment_ID = "%s(%d,%d)_%s_%s_bs(%d)lr(%.4f_%d_%.1f)m(%.2f)e(%d)act(%s)xavier(yes)2" % (type(net).__name__, hidden_neurons1, hidden_neurons2, type(criterion).__name__, type(optimizer).__name__, batch_size, learning_rate, lr_step_size, lr_gamma, momentum, epochs, type(activation).__name__)
os.makedirs("./" + experiment_ID)
dataset_train = torchvision.datasets.MNIST("./mnist", train=True, download=True)
valid_and_test_set = torchvision.datasets.MNIST("./mnist", train=False, download=True)
dataset_valid, dataset_test = torch.utils.data.random_split(valid_and_test_set,[5000, 5000]
mu = dataset_train.data.float().mean()
std = dataset_train.data.float().std()
class Convert(object):
def __call__(self, img):
return torch.unsqueeze(torch.from_numpy(np.array(img)), 0).float()
class Flatten(object):
def __call__(self, img):
return img.view(28*28)
class OneHot(object):
def __call__(self, label):
#target = torch.zeros(10, dtype=torch.float)
#target[label] = 1.0
return label
transform_default = transforms.Compose(
[Convert(),
transforms.Normalize(mean=[mu], std=[std]),
Flatten()])
dataset_train.transform = transform_default
dataset_train.target_transform = OneHot()
dataset_valid.dataset.transform = transform_default
dataset_valid.dataset.target_transform = OneHot()
dataloader_train = torch.utils.data.DataLoader(dataset_train, batch_size=batch_size, shuffle=True, num_workers=num_workers, pin_memory=True)
dataloader_valid = torch.utils.data.DataLoader(dataset_valid, batch_size=5000, num_workers=num_workers, pin_memory=True)
def train(dataset, dataloader):
net.train()
loss_sum = 0.0
correct = 0
for batch in dataloader:
inputs, targets = batch
inputs, targets = inputs.to(device, non_blocking=True), targets.to(device, non_blocking=True)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
loss_sum += loss.item()
outputs_max = torch.argmax(outputs, dim=1)
targets_max = targets #torch.argmax(targets, dim=1)
correct += outputs_max.eq(targets_max).sum().float()
scheduler.step()
return loss_sum / len(dataloader), 100. * correct / len(dataset)
def test(dataset, dataloader, valid=True):
net.eval()
i=0
a=0
with torch.no_grad():
for batch in dataloader:
inputs = batch[0]
label=batch[1]
inputs = inputs.to(device, non_blocking=True)
outputs = net(inputs)
predictions = torch.argmax(outputs, dim=1)
return predictions
t0 = time.time()
if not pretrained:
losses = []
train_accuracies = []
valid_accuracies = []
ticks = []
net.to(device)
for epoch in range(1, epochs+1):
avg_loss, accuracy_train = train(dataset_train, dataloader_train)
predictions = test(dataset_valid, dataloader_valid)
accuracy_valid = 100. * predictions.eq(dataset_valid.dataset.targets[dataset_valid.indices].to(device)).sum().float() / len(dataset_valid)
losses.append(avg_loss)
train_accuracies.append(accuracy_train)
valid_accuracies.append(accuracy_valid)
ticks.append(epoch)
torch.save({
'net': net,
'accuracy': max(valid_accuracies),
'epoch': epoch
}, "./" + experiment_ID +'/epo:' + str(epoch) + ".tar")
print('\rEnded the {} epoch on a total of {} epochs ({}%)'.format(epoch, epochs, round(100*epoch/epochs, 2)), end='', flush=True)
If I’ve cut some relevant code, please let my know and I’ll edit the post.
Thenks for helping.