Hi Charles, thanks for the reply.
I am not able to define qconfigs to each module with my limited coding knowledge. Can you please help me with lines of code to run it without error.
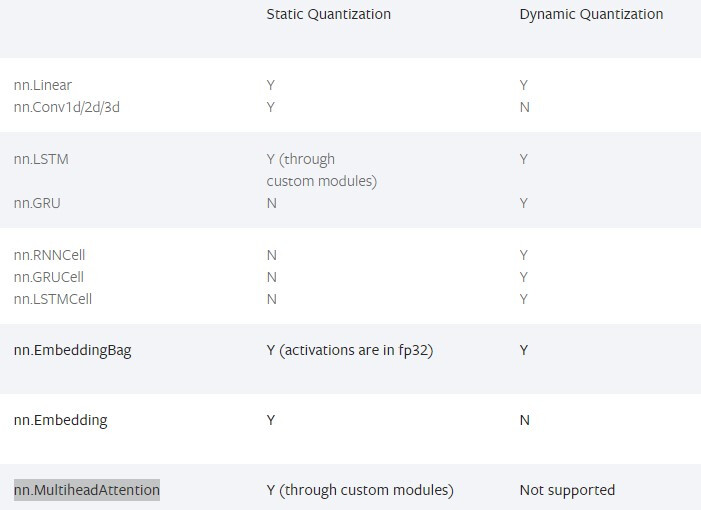
PFA model architecture, which helps you to define qconfigs. Please help me!!
model.transformer_module name mod Mask2FormerTransformerModule(
(position_embedder): Mask2FormerSinePositionEmbedding()
(queries_embedder): Embedding(100, 256)
(queries_features): Embedding(100, 256)
(decoder): Mask2FormerMaskedAttentionDecoder(
(layers): ModuleList(
(0-3): 4 x Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mask_predictor): Mask2FormerMaskPredictor(
(mask_embedder): Mask2FormerMLPPredictionHead(
(0): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(1): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(2): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Identity()
)
)
)
)
(level_embed): Embedding(3, 256)
)
model.transformer_module.position_embedder name mod Mask2FormerSinePositionEmbedding()
model.transformer_module.queries_embedder name mod Embedding(100, 256)
model.transformer_module.queries_features name mod Embedding(100, 256)
model.transformer_module.decoder name mod Mask2FormerMaskedAttentionDecoder(
(layers): ModuleList(
(0-3): 4 x Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mask_predictor): Mask2FormerMaskPredictor(
(mask_embedder): Mask2FormerMLPPredictionHead(
(0): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(1): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(2): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Identity()
)
)
)
)
model.transformer_module.decoder.layers name mod ModuleList(
(0-3): 4 x Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
)
model.transformer_module.decoder.layers.0 name mod Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
model.transformer_module.decoder.layers.0.self_attn name mod Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.0.self_attn.k_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.self_attn.v_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.self_attn.q_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.self_attn.out_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.activation_fn name mod ReLU()
model.transformer_module.decoder.layers.0.self_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.0.cross_attn name mod MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.0.cross_attn.out_proj name mod NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.cross_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.0.fc1 name mod Linear(in_features=256, out_features=2048, bias=True)
model.transformer_module.decoder.layers.0.fc2 name mod Linear(in_features=2048, out_features=256, bias=True)
model.transformer_module.decoder.layers.0.final_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.1 name mod Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
model.transformer_module.decoder.layers.1.self_attn name mod Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.1.self_attn.k_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.self_attn.v_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.self_attn.q_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.self_attn.out_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.activation_fn name mod ReLU()
model.transformer_module.decoder.layers.1.self_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.1.cross_attn name mod MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.1.cross_attn.out_proj name mod NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.cross_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.1.fc1 name mod Linear(in_features=256, out_features=2048, bias=True)
model.transformer_module.decoder.layers.1.fc2 name mod Linear(in_features=2048, out_features=256, bias=True)
model.transformer_module.decoder.layers.1.final_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.2 name mod Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
model.transformer_module.decoder.layers.2.self_attn name mod Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.2.self_attn.k_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.self_attn.v_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.self_attn.q_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.self_attn.out_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.activation_fn name mod ReLU()
model.transformer_module.decoder.layers.2.self_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.2.cross_attn name mod MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.2.cross_attn.out_proj name mod NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.cross_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.2.fc1 name mod Linear(in_features=256, out_features=2048, bias=True)
model.transformer_module.decoder.layers.2.fc2 name mod Linear(in_features=2048, out_features=256, bias=True)
model.transformer_module.decoder.layers.2.final_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.3 name mod Mask2FormerMaskedAttentionDecoderLayer(
(self_attn): Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(cross_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
(cross_attn_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=256, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=256, bias=True)
(final_layer_norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
model.transformer_module.decoder.layers.3.self_attn name mod Mask2FormerAttention(
(k_proj): Linear(in_features=256, out_features=256, bias=True)
(v_proj): Linear(in_features=256, out_features=256, bias=True)
(q_proj): Linear(in_features=256, out_features=256, bias=True)
(out_proj): Linear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.3.self_attn.k_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.self_attn.v_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.self_attn.q_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.self_attn.out_proj name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.activation_fn name mod ReLU()
model.transformer_module.decoder.layers.3.self_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.3.cross_attn name mod MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
)
model.transformer_module.decoder.layers.3.cross_attn.out_proj name mod NonDynamicallyQuantizableLinear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.cross_attn_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layers.3.fc1 name mod Linear(in_features=256, out_features=2048, bias=True)
model.transformer_module.decoder.layers.3.fc2 name mod Linear(in_features=2048, out_features=256, bias=True)
model.transformer_module.decoder.layers.3.final_layer_norm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.layernorm name mod LayerNorm((256,), eps=1e-05, elementwise_affine=True)
model.transformer_module.decoder.mask_predictor name mod Mask2FormerMaskPredictor(
(mask_embedder): Mask2FormerMLPPredictionHead(
(0): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(1): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(2): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Identity()
)
)
)
model.transformer_module.decoder.mask_predictor.mask_embedder name mod Mask2FormerMLPPredictionHead(
(0): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(1): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
(2): Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Identity()
)
)
model.transformer_module.decoder.mask_predictor.mask_embedder.0 name mod Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
model.transformer_module.decoder.mask_predictor.mask_embedder.0.0 name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.mask_predictor.mask_embedder.0.1 name mod ReLU()
model.transformer_module.decoder.mask_predictor.mask_embedder.1 name mod Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
)
model.transformer_module.decoder.mask_predictor.mask_embedder.1.0 name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.mask_predictor.mask_embedder.1.1 name mod ReLU()
model.transformer_module.decoder.mask_predictor.mask_embedder.2 name mod Mask2FormerPredictionBlock(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): Identity()
)
model.transformer_module.decoder.mask_predictor.mask_embedder.2.0 name mod Linear(in_features=256, out_features=256, bias=True)
model.transformer_module.decoder.mask_predictor.mask_embedder.2.1 name mod Identity()
model.transformer_module.level_embed name mod Embedding(3, 256)
class_predictor name mod Linear(in_features=256, out_features=29, bias=True)
criterion name mod Mask2FormerLoss(
(matcher): Mask2FormerHungarianMatcher()
)
criterion.matcher name mod Mask2FormerHungarianMatcher()