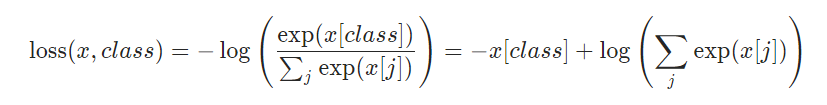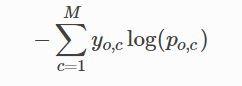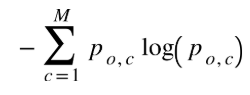I was wondering why the negative log likelihood function (NLLLoss()) in torch.nn expected a target. The torch.nn.NLLLoss() uses nll_loss(input, target, weight=self.weight, ignore_index=self.ignore_index, reduction=self.reduction) in his forward call. If NLL has the format : , why is the target vector needed to compute this, and not just the output of our nn.Softmax() layer?
From what I understand, this function never uses the label (or target) of the sample to compute the probability output for class, since x[class] refers to the probability of our sample belonging to class, and sum(exp (x[j]) is just the sum over the exponential of outputs for all classes. So where does Pytorch actually use the label of the sample in this loss function? I feel I’m missing something
Related to this, I’m actually trying to tweak this loss function. I’d like to replace the target (y_o,c) in the loss function below by the prediction probability output for a specific class p_o,c, basically turning this
into this
I tried simply replacing the target argument by outputs again when calling a CrossEntropyLoss() object, but Pytorch expects a datatype torch.long, not a torch.float as it is the case with outputs. Do you have any idea how I could obtain this new loss function?
If you are looking for label smoothing, this thread might have an interesting code snippet.
Alternatively, you could just write out the formula.
I’m not sure, how p_o,c is defined, but I guess it should be the probability of class c for output o?
If we’re talking mini-batch training, p_o,c would be an array of size (batch_size x num_classes), representing for each sample in th mini-batch it’s probability distribution over all possible classes. My concern was that I wanted a backpropagatable loss function. I’ll try that line and come back to you.
I think this is incorrect and nll_loss already assumes that you pass log(probabilities). You test this by giving it just probabilities (onehot format with values in range [0, 1]) and it will give you negative values.
for data, target in test_loader:
data, target = data.to(device), target.to(device)
data.requires_grad = True
output = model(data)
init_pred = output.max(1, keepdim=True)[1]
# get the index of the max log-probability
# Calculate the loss
loss1 = F.nll_loss(output, target)
label = output.argmax(1)
criterion = nn.CrossEntropyLoss()
loss2 = criterion(output, label)
Using 1-element tensors for target and label (which is created via output.argmax(1)) indicates batch_size=1 as well as nb_classes=1, which is not a valid multi-class classification use case.
However, even then the losses differ and are not equal due to the reasons I’ve posted above:
batch_size = 1
nb_classes = 1
# initialize the model output as logits
output = torch.randn(batch_size, nb_classes, requires_grad=True)
target = torch.randint(0, nb_classes, (batch_size,))
# this is wrong since log-probabilities are expected
loss1 = F.nll_loss(output, target)
criterion = nn.CrossEntropyLoss()
# this is also wrong since another target is used
label = output.argmax(1)
loss2 = criterion(output, label)
# compare
print(loss1 - loss2)
# tensor(0.5912, grad_fn=<SubBackward0>)
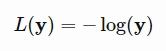 , why is the target vector needed to compute this, and not just the output of our nn.Softmax() layer?
, why is the target vector needed to compute this, and not just the output of our nn.Softmax() layer?