Hello there.
I’m trying to re-implement a TensorFlow-based tutorial using PyTorch.
- The original code is provided here: Calmcode - embeddings: Experiment.
- The training data is available here: https://calmcode.io/datasets/headlines.zip
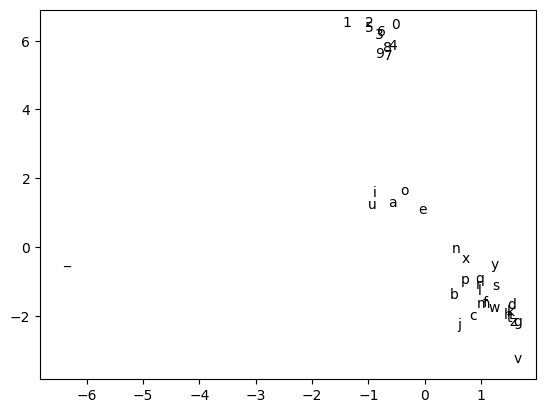
The tutorial aims to provide a brief introduction to embeddings. This is achieved by implementing a trivial model trained on characters bi-grams i.e. given a character the model predicts the one that’s most likely to follow. As the model relies on an embedding layer (tensorflow.keras.layers.Embedding), once the training is completed the representations of the characters can be extracted from this layer and plotted to observe how they form different clusters:
Despite including a ReLU, which is not part of the original implementation, my model seems to underperfom. For a 10-epoch experiment, the CrossEntropyLoss stops decreasing after just 4 epochs. This happens no matter the configuration I try: linear models, non linear models, smaller or larger batches, same or different hyperparameters… As an example, these are the losses I got for the implementation below:
[142984.93111598492, 135160.47544932365, 134044.4788825512, 132994.69680345058, 132919.3438794613, 132876.14006257057, 132842.30431377888, 132821.3758159876, 132801.9429345131, 132783.21744656563]
This is the last model implementation I tested:
import torch.nn as nn
class BigramCharModel(nn.Module):
def __init__(self, vocab_size, embed_size):
super().__init__()
self._embeddings = nn.Embedding(vocab_size, embed_size)
self._layer_stack = nn.Sequential(
nn.Linear(embed_size, vocab_size),
nn.ReLU()
)
def forward(self, input):
embeddings = self._embeddings(input)
logits = self._layer_stack(embeddings)
return logits
The is the custom-dataset implementation:
import itertools as it
import pandas as pd
from pathlib import Path
from sklearn.preprocessing import LabelEncoder
from typing import Generator
from torch.utils.data import Dataset
class CharPairsDataset(Dataset):
def __init__(self, data_filename: str) -> None:
self._data_path = Path(__file__).parent.parent / f"data/{data_filename}"
self._encoder = LabelEncoder()
self._df = self._read_into_df(self._data_path)
def _get_bigrams(self, text: str) -> Generator:
"""Returns a generator object that, for a given text, produces its
corresponding charaters bigrams.
Args:
text (str): Input string from which the charaters bigrams are
generated.
Returns:
Generator: A generator object that yields pairs of characters
representing the bigrams in the input text.
"""
text = text.replace(" ", "_")
for i in range(len(text) - 1):
yield text[i], text[i + 1]
def _read_into_df(self, data_path: Path) -> pd.DataFrame:
# read text data into a dataframe, ignoring NA values
data = pd.read_csv(data_path).loc[lambda d: ~d["text"].isna()]["text"][:20_000]
# get chars. bigrams for each text in data and store them in a df
# first col.: input char; second col.: char to be predicted
bigrams = list(it.chain(*[self._get_bigrams(txt) for txt in data]))
df = pd.DataFrame(bigrams)
self._encoder.fit(df[0].unique())
df[0] = self._encoder.transform(df[0])
df[1] = self._encoder.transform(df[1])
return df
def __len__(self) -> int:
return len(self._df)
# TODO: add output typing
def __getitem__(self, index: int):
input_char = self._df.iloc[index, 0]
output_char = self._df.iloc[index, 1]
return input_char, output_char
This is my main.py where the training loop is implemented:
import joblib
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from tqdm import tqdm
from dataset import CharPairsDataset
from model import BigramCharModel
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataset = CharPairsDataset("headlines.zip")
dloader = DataLoader(dataset, batch_size=16, shuffle=True, num_workers=16)
encoder = dataset._encoder
vocab_size = len(encoder.classes_)
if __name__ == "__main__":
losses = []
loss_function = nn.CrossEntropyLoss()
model = BigramCharModel(vocab_size=vocab_size, embed_size=2).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in tqdm(range(10)):
model.train()
total_loss = 0
for data in dloader:
optimizer.zero_grad()
x = data[0].to(device)
y = data[1].to(device)
logits = model(x)
loss = loss_function(logits, y)
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
torch.save(model.state_dict(), "trained_model.pt")
joblib.dump(encoder, "label_encoder.joblib")
print(losses)
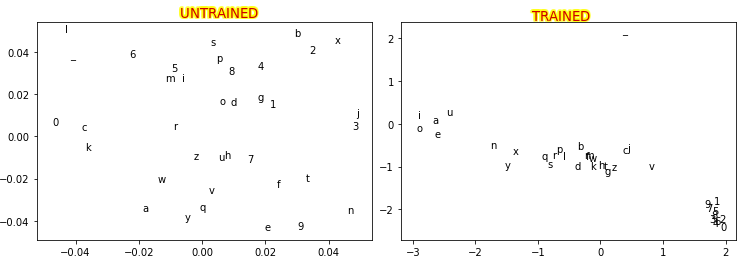
Finally, this is the scatter plot of the embeddings I obtain after a 10-epoch run. Unfortunately, the situation doesn’t improve even after a 20-epoch run. I never managed to obtain a result comparable to the right plot above.
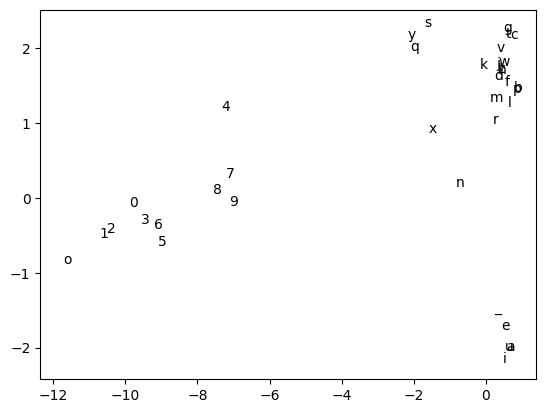
The previous plot was generated with the following bit of code:
import matplotlib.pyplot as plt
import torch
import joblib
from model import BigramCharModel
encoder = joblib.load("label_encoder.joblib")
vocab_size = len(encoder.classes_)
model = BigramCharModel(vocab_size=vocab_size, embed_size=2)
model.load_state_dict(torch.load("trained_model.pt"))
model.eval()
classes = encoder.classes_
labels = encoder.transform(classes)
e = model._embeddings.weight.detach().cpu().numpy()
plt.scatter(x=e[:, 0], y=e[:, 1], alpha=0)
for i in labels:
plt.text(e[i, 0], e[i, 1], encoder.inverse_transform([i])[0])
plt.show()