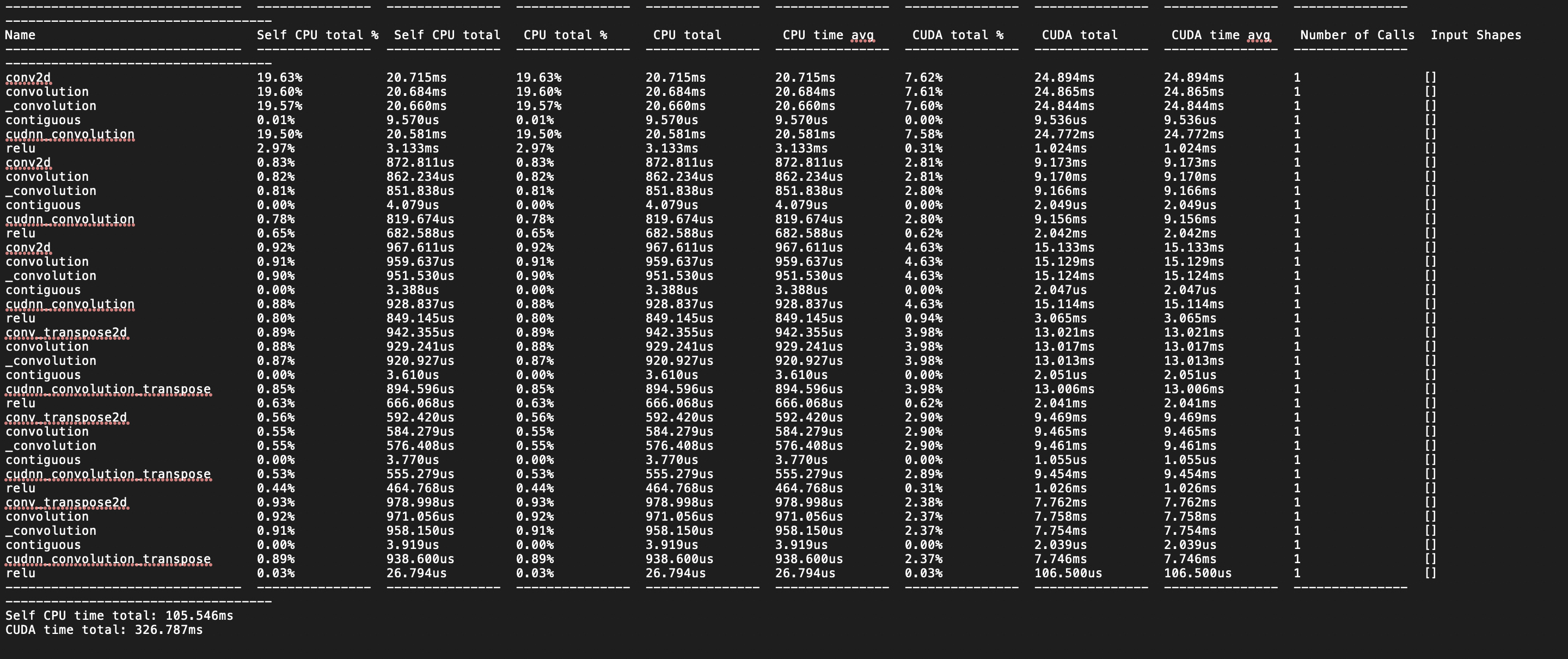
I was trying to implement a simple CAE in Pytorch. I am seeing a lot of difference in train time in pytorch compared to tensorflow. Pytorch version is taking around 20 sec for 100 epochs whereas tensorflow version is taking around 5 sec for 100 epochs. Can anyone help me resolve this ? I have attached my code below.
Tensorflow code is similar to this https://github.com/panji1990/Deep-subspace-clustering-networks/blob/master/Pre-Train-Conv-AE-EYaleB.py
Also nvidia-smi shows 100% usage for pytorch version whereas it is around 45% for tensorflow version
class fullmodel(nn.Module):
def __init__(self,kernel_size,batch_size,num_class):
super(fullmodel, self).__init__()
self.batch_size = batch_size
self.enc1 = nn.Conv2d(1,10,kernel_size[0],padding = 2)
self.enc2 = nn.Conv2d(10,20,kernel_size[1],padding = 1)
self.enc3 = nn.Conv2d(20,30,kernel_size[2],padding = 1)
self.dec1 = nn.ConvTranspose2d(30,20,kernel_size = 3,padding = 1)
self.dec2 = nn.ConvTranspose2d(20,10,kernel_size = 3,padding = 1)
self.dec3 = nn.ConvTranspose2d(10,1,kernel_size = 5,padding = 2)
def forward(self,x):
enc_out = F.relu(self.enc3(F.relu(self.enc2(F.relu(self.enc1(x))))))
dec_out = F.relu(self.dec3(F.relu(self.dec2(F.relu(self.dec1(enc_out))))))
return enc_out,dec_out,
def train(model,data):
torch.backends.cudnn.benchmark = True
lr = 1e-3
num_epochs = 5000
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
X = torch.from_numpy(data).float()
#data_train = torch.utils.data.DataLoader(dataset=X, batch_size=data.shape[0])
parameters = model.parameters()
model.apply(init_weights)
optim = torch.optim.Adam(model.parameters(), lr=lr)
model = model.to(device)
model = model.train()
X = X.to(device)
time1 = time.time()
for epoch in range(num_epochs):
avg_recon_loss = 0
latent,output = model(X)
recon_loss = 0.5*(torch.sum((output - X)**2))
optim.zero_grad()
recon_loss.backward()
optim.step()
avg_recon_loss += recon_loss
if (epoch+1)%100 == 0:
print("Iter : ",epoch+1)
print ("Loss : {:.4f}".format(avg_recon_loss/(38*64)))
print(time.time() - time1)
time1 = time.time()
if __name__ == "__main__":
data = sio.loadmat("../datasets/YaleBCrop025.mat")
imgs = data['Y']
I = []
Label = []
for i in range(imgs.shape[2]):
for j in range(imgs.shape[1]):
temp = np.reshape(imgs[:,j,i],[42,48])
Label.append(i)
I.append(temp)
I = np.array(I)
n_input = [42,48]
imgs = np.reshape(I, [I.shape[0], 1, n_input[0], n_input[1]])
kernel_size = [5,3,3]
classes = 38
batch_size = classes*64
model = fullmodel(kernel_size,classes,batch_size)
train(model,imgs)