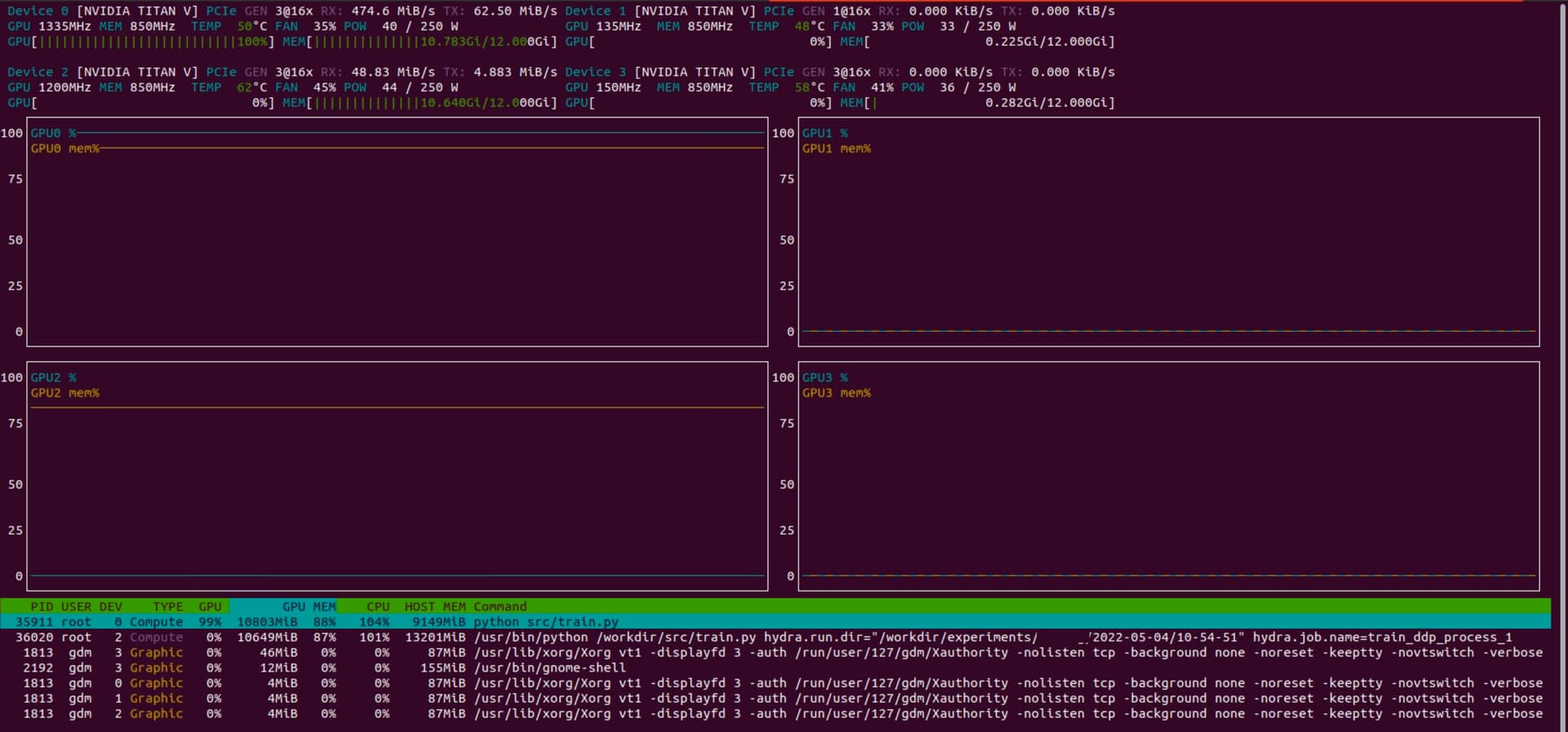
I’m training a model on image and text input pairs from Flickr30k. Nothing special, just a Resnet18 for image and an Embedding + GRU network for text.
I’m training the model with Pytorch Lightning running on two GPUs with a DDP strategy, 16-bit precision, 512 batch size, and 8 workers in total. I defined a ModelCheckpoint that saves the 5 best iterations and an EarlyStopping callback. Both callbacks monitor the val_loss.
def train_dataloader(self) -> DataLoader:
return DataLoader(
self.train_data,
batch_size=self.batch_size,
num_workers=self.conf.data.num_workers,
pin_memory=True,
shuffle=True,
drop_last=True,
collate_fn=collate_fn,
)
def val_dataloader(self) -> DataLoader:
return DataLoader(
self.val_data,
batch_size=self.batch_size,
num_workers=self.conf.data.num_workers,
pin_memory=True,
drop_last=True,
collate_fn=collate_fn,
)
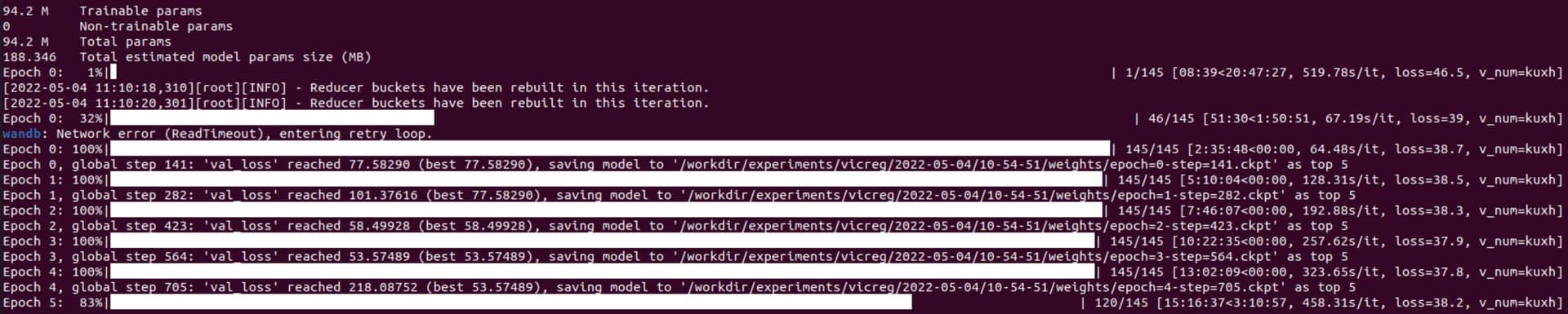
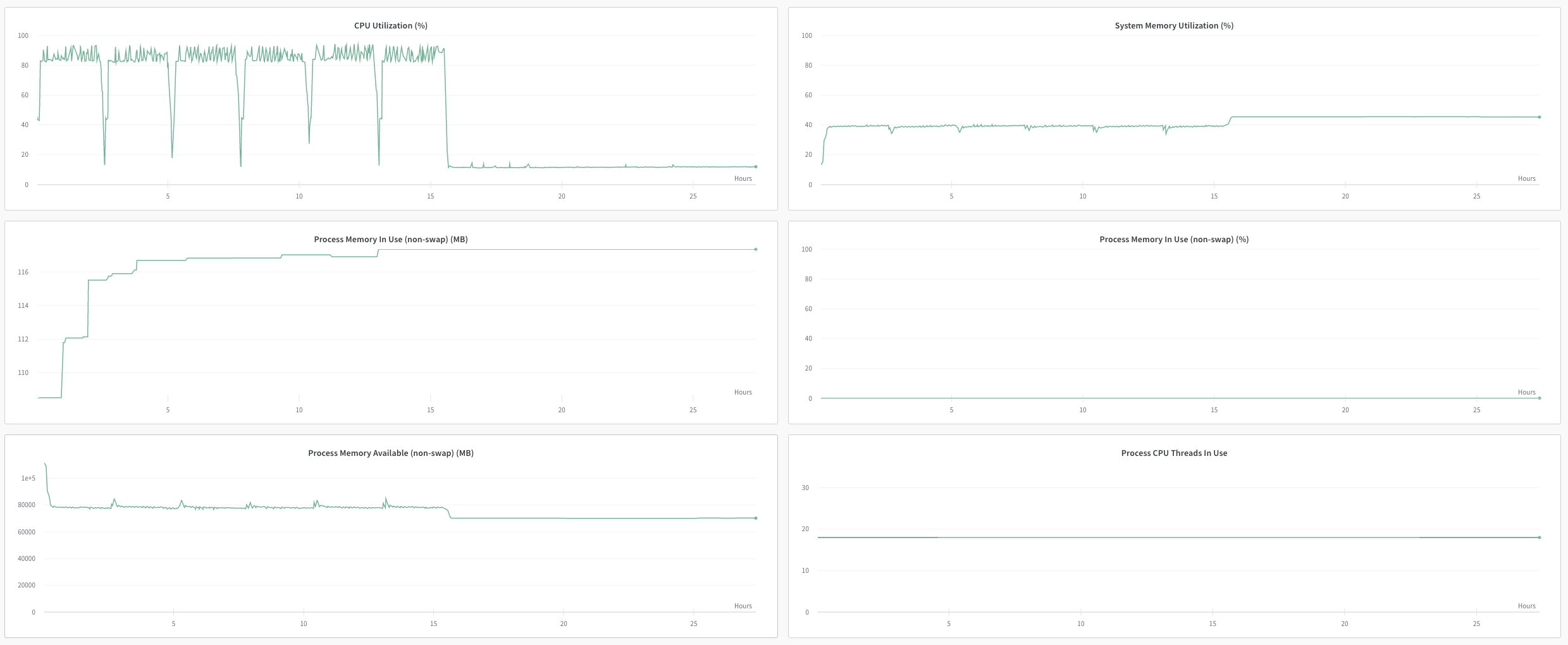
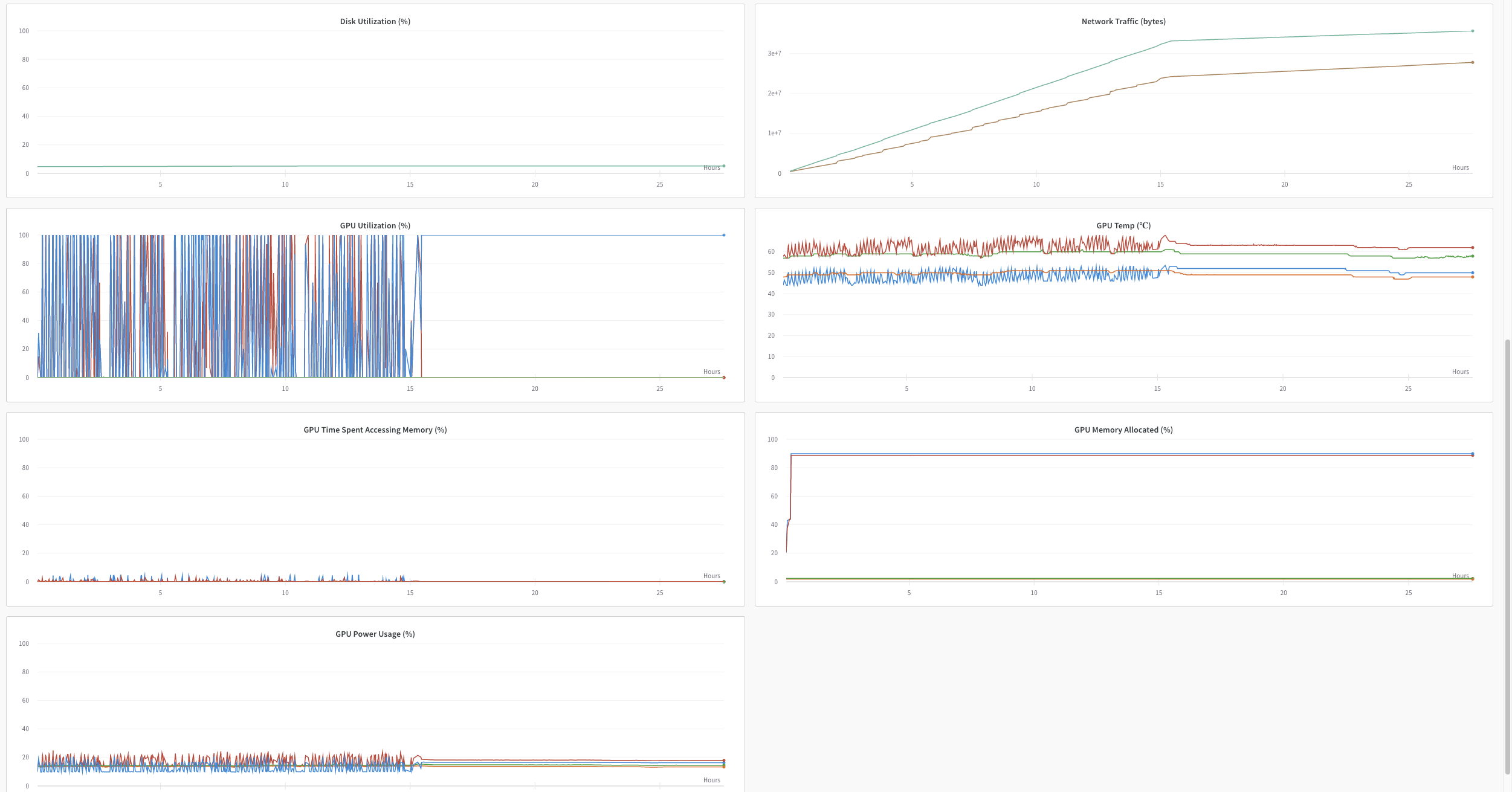
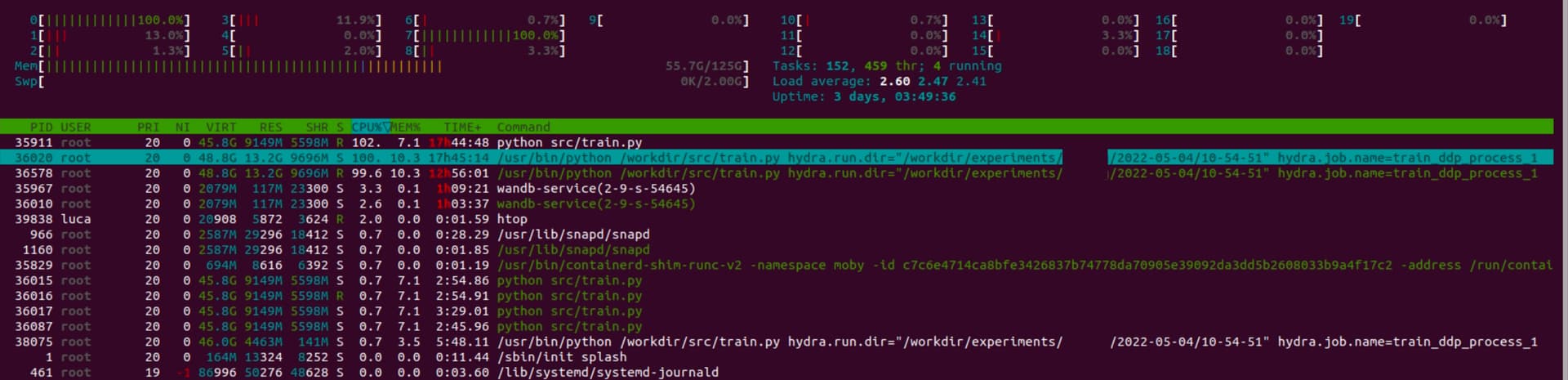
The problem is that after starting the sixth epoch, the model appears to have entered an infinite loop. There is a 100% used GPU and CPU usage has dropped dramatically. I can’t understand where the problem may be. Some idea?