Hello, it is my first time in the forum
Recently I am doing a medical image research, which requires loading a very big pathology slide(about 5GBytes), and doing some CNN jobs.
Problem
Is it possible to run dataloading and model.run() in an async fashion (producer and consumer)?
- model.run() is executing in GPU
- dataloading() is executing in CPU
I have understand the ideas and usage of python asyncio library
And the toy example works fine below
Toy example code and profiling result
- Code
(reason I set wait_consumer to 3.2 and wait_producer to 1.7 is because that in the real scenario, the consumer (model.run()takes 320 sec to finish while 170 forimgloader)
wait_consumer = 3.2
wait_pdocuer = 1.7
async def consumer(q):
while True:
x, xx = await q.get()
q.task_done()
async def producer(q, n):
for x in range(n):
await asyncio.sleep(wait_producer) # IO takes time for 10 sec
await q.put((x, x * x))
async def async_main(n):
q = asyncio.Queue()
consumers = asyncio.ensure_future(consumer(q))
await producer(q, n)
await q.join()
consumers.cancel()
def main_run_async(n):
t_start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(async_main(n))
loop.close()
t_end = time.time()
return t_end - t_start
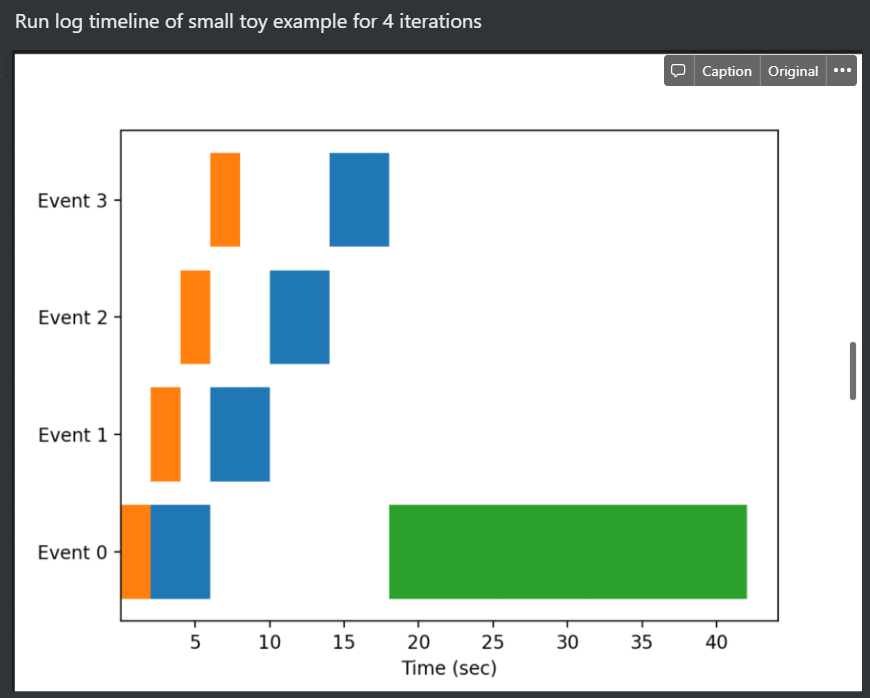
- Profiling the results
The async property works well, the orange and blue bar symbolizes the async, producer and consumer version while the green bar is the naïve serial one.
Project code
- Now change the asyncio.sleep() to real code in my research project (some of the name has been hidden due to confidentiality, but most of the architecture works fine and very similar to that of above)
async def model_run_async(model):
model.run() # Model run in GPU
async def fun_consumer(q, args):
while True:
iteration, img_loader = await q.get() # Popped the produced img_loader from queue
model = ProjectModel(
image_loader=img_loader,
image_size=args.img_size,
)
print('[ASYNC LOG CONS] Start time {}'.format(time.time() - t_zero))
t_consumer_start.append(time.time() - t_zero)
await model_run_async(model)
t_consumer_end.append(time.time() - t_zero)
print('[ASYNC LOG CONS] End time {}'.format(time.time() - t_zero))
q.task_done()
async def image_load_async(args):
img_loader = BaselineImageLoader(
slide_path=args.slide_path,
resize_ratio=args.resize_ratio,
img_size=args.img_size,
)
return img_loader
async def fun_producer(q, args):
for iteration in range(args.iters):
print('[ASYNC LOG PROD] Start time {}'.format(time.time() - t_zero))
t_producer_start.append(time.time() - t_zero)
img_loader = await image_load_async(args) # block here and hope I can run consumer in this stage (train the last-batch data during loading the current batch of data)
# Load big medical slide data in CPU
print('[ASYNC LOG PROD] End time {}'.format(time.time() - t_zero))
q.put((iteration, img_loader)) # Put into queue
t_producer_end.append(time.time() - t_zero)
async def async_main(args):
q = asyncio.Queue()
consumers = asyncio.ensure_future(fun_consumer(q, args))
await fun_producer(q, args)
await q.join()
consumers.cancel()
def main_run_async(args):
t_start = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(async_main(args))
loop.close()
t_end = time.time()
return t_end - t_start
- Profiling the results
Only the producer seems to be executing while the consumer does not work similar to that of the toy example (Sorry that I cannot post more than 1 image)
[ASYNC LOG PROD] Start time 0, End time 166
[ASYNC LOG PROD] Start time 166, End time 332
[ASYNC LOG PROD] Start time 332, End time 499
… etc, but WITHOUT THE LOG FROM CONSUMER (model run)
Thank you very much in advance for the kindness help, it really helps my research.