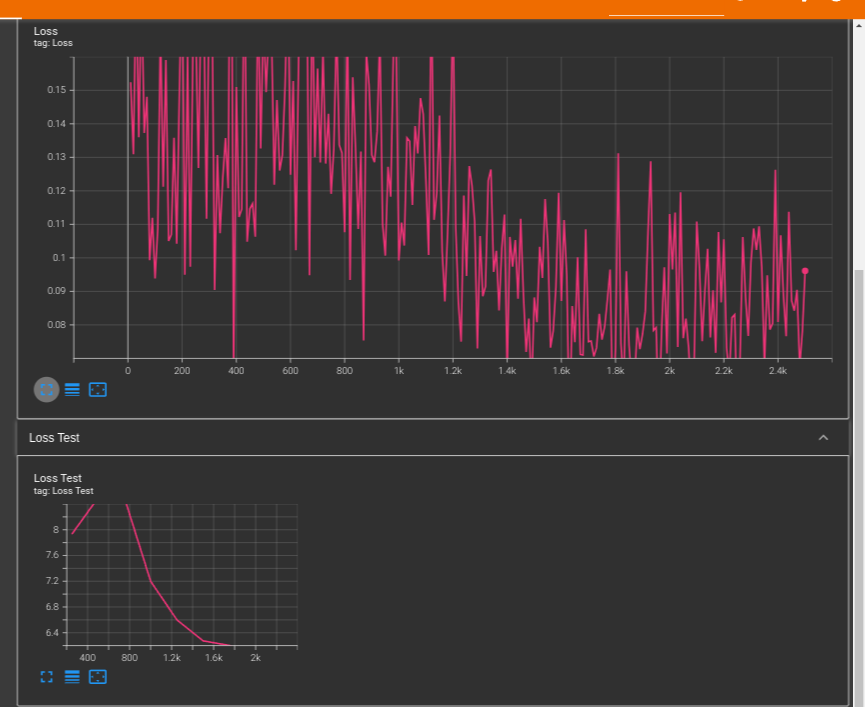
Hello, I train a transformer model to generate a latent space and then decode this latent space to produce raw audio, which I use to compute my loss. I don’t want to train the decoder model itself (it works well and I don’t have a lot of RAM), so I disabled its gradients by using:
for param in self.autoencoder.parameters():
param.requires_grad = False
self.autoencoder.eval()
in the dataset class.
Then, I compute the loss of the decoded audio against the base waveform using MSE loss. The loss gives me a number, and then I call the backward() function.
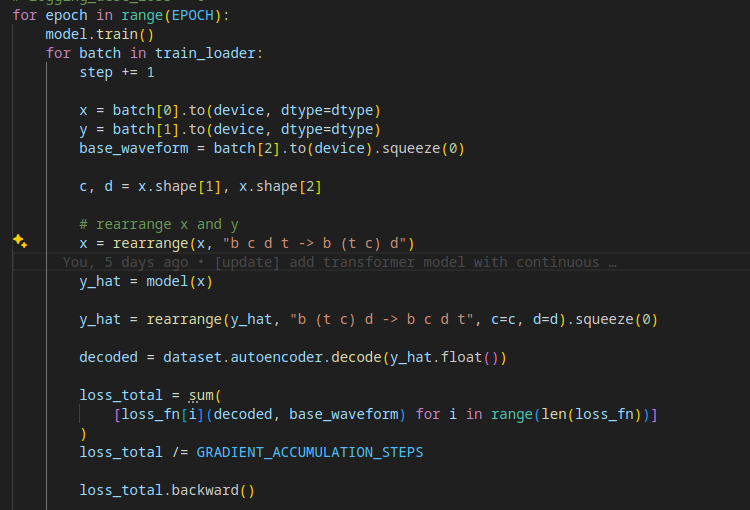
The problem is that my model doesn’t progress at all. I don’t think the loss_total.backward() has any effect because the loss doesn’t change.
EPOCH 0.0 (0.01%) - STEP 10: Loss 0.0229 LR 9.999e-05
EPOCH 0.0 (0.03%) - STEP 20: Loss 0.0344 LR 9.997e-05
EPOCH 0.0 (0.04%) - STEP 30: Loss 0.0252 LR 9.996e-05
EPOCH 0.0 (0.05%) - STEP 40: Loss 0.0149 LR 9.995e-05
EPOCH 0.0 (0.07%) - STEP 50: Loss 0.0325 LR 9.993e-05
EPOCH 0.0 (0.08%) - STEP 60: Loss 0.0124 LR 9.992e-05
EPOCH 0.0 (0.09%) - STEP 70: Loss 0.0191 LR 9.991e-05
EPOCH 0.0 (0.11%) - STEP 80: Loss 0.029 LR 9.989e-05
EPOCH 0.0 (0.12%) - STEP 90: Loss 0.0179 LR 9.988e-05
EPOCH 0.0 (0.13%) - STEP 100: Loss 0.0289 LR 9.987e-05
EPOCH 0.0 (0.15%) - STEP 110: Loss 0.0381 LR 9.985e-05
EPOCH 0.0 (0.16%) - STEP 120: Loss 0.0263 LR 9.984e-05
EPOCH 0.0 (0.17%) - STEP 130: Loss 0.0234 LR 9.983e-05
If I change the loss to compute the MSE loss on y_hat (the latent space) and y (the target latent space), the model works. Do you have any idea why the loss on the decoded audio doesn’t have any effect?
The decoder is just a set of strides convolution block (from the DAC model)