On my machine I was able to train a CNN using:
PyTorch 1.6.0 and
Cuda compilation tools, release 11.6, V11.6.112
Build cuda_11.6.r11.6/compiler.30978841_0
I needed more memory to expand my testing, so I ported my code to Google CoLab using the T4 GPU instance. Every time I run the code, I keep getting an exception when I run the loss function nn.CrossEntropyLoss() during training. I make sure to reset the session between runs.
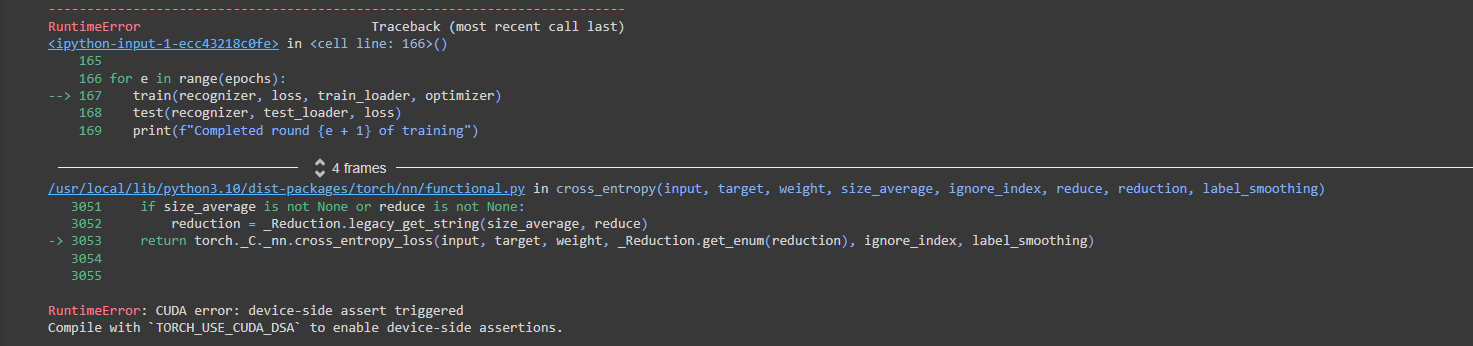
The exception ends at:
I looked at the implementation:
to see where an exception or error message may be raised, but it seems like the exceptions that can be raised are mostly due to preconditions. These preconditions shouldn’t be violated because I don’t configure nn.CrossEntropyLoss() at all.
I added
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
import torch
import torchvision
from torch import nn
To the top of my code block, but I still can’t seem to get any useful error message. When I looked at the implementation of cross entropy on my machine, I noticed that it is different from what is currently implemented in functional.py:
if not torch.jit.is_scripting():
tens_ops = (input, target)
if any([type(t) is not Tensor for t in tens_ops]) and has_torch_function(tens_ops):
return handle_torch_function(
cross_entropy, tens_ops, input, target, weight=weight,
size_average=size_average, ignore_index=ignore_index, reduce=reduce,
reduction=reduction)
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
In the older version, it calls nll_loss and passes as a first argument the softmax of the input, which doesn’t seem to happen now:
if size_average is not None or reduce is not None:
reduction = _Reduction.legacy_get_string(size_average, reduce)
return torch._C._nn.cross_entropy_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index, label_smoothing)
Here is my training code:
def train(network, loss, loader, optimizer):
network.train()
for batch_index, (image_tensor, target_output) in enumerate(loader):
image_tensor = image_tensor.float().cuda()
target_output = target_output.cuda()
logits = network(image_tensor)
print(f"Logits shape: {logits.shape} of {logits}")
#print(f"Target: {target_output.shape} of {target_output}")
result = loss(logits, target_output)
result.backward()
optimizer.step()
optimizer.zero_grad()
I also tried passing in softmax’d input to the loss function over in my CoLab code block, but that didn’t seem to make any difference. The documentation says that the input should be unnormalized logits and they appear to be:
[-8.3126e-01, -9.1190e-01, 8.6249e-01, -2.0465e-02, -8.8040e-01,
5.0193e-02, -4.5052e-02, 7.8031e-02, 4.2935e-01, -1.3772e-01,
-6.2306e-01, 9.9225e-02, 7.3910e-01, 2.2487e-01, 8.8633e-02,
3.9571e-01, 2.3213e-01, -2.1260e-01, -3.4335e-01, 1.3615e-01,
-5.2874e-01, 1.5202e-01, -7.1269e-02, 4.8146e-01, 3.4631e-01]
Any ideas? I cannot change the CUDA or PyTorch versions on my machine. It is old and space is becoming an issue.
Thanks for any help!