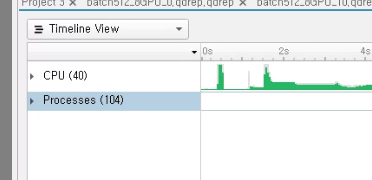
What are these processes assigned to?
Could you extend the drop down menu and compare both machines?
Also, how many CPUs does the RTX2080Ti workstation have? Note that your DGX station reports 40, which might also be the reason why it’s able to use more processes.
Now I guess very long allreduce and Broadcast which caused by late Memcpy H2D. If you see the above figure GPU 1,3,4 call the H2D(=green bar) at the similar time, but GPU 2 called the H2D at late. These unsync behavior make inefficient at multi-GPU training.
So all GPU sync on GPU2, can I solve this problem…? For example, I allocated the memcpyH2D to new stream or any nice idea…?