I saw the link
https://pytorch.org/tutorials/recipes/mobile_perf.html#setup
how to optimize the model. But I got stuck in model preparation.
How can I use my model to replace the code below?
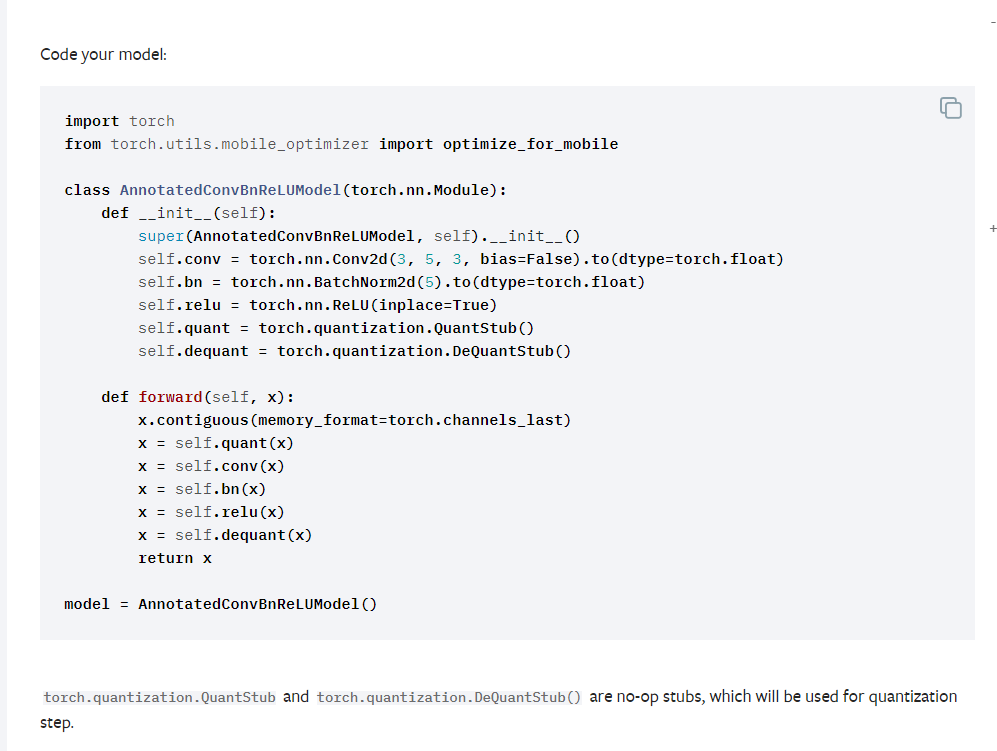
That part of perf optimization refers to quantization step. If you want to quantize your model, you may want to follow this Quantization — PyTorch 1.9.0 documentation, (beta) Static Quantization with Eager Mode in PyTorch — PyTorch Tutorials 1.9.0+cu102 documentation, Quantization Recipe — PyTorch Tutorials 1.9.0+cu102 documentation. You can google “pytorch quantization” and get some more links.
If you are not trying to quantize the model then you can ignore that step.
Thanks for the reply, @kimishpatel
And I meet an issue when I run this code:
subnet.qconfig = torch.quantization.default_qconfig
print(subnet.qconfig)
print(torch.backends.quantized.supported_engines)
subnet.qconfig = torch.quantization.get_default_qconfig('qnnpack')
torch.backends.quantized.engine = 'qnnpack'
torch.quantization.prepare(subnet, inplace=True)
torch.quantization.convert(subnet, inplace=True)
#optimize
But it prints these errors:
['none']
terminate called after throwing an instance of 'c10::Error'
what(): quantized engine QNNPACK is not supported
Exception raised from setQEngine at /media/nvidia/WD_NVME/PyTorch/JetPack_4.4.1/pytorch-v1.8.0/aten/src/ATen/Context.cpp:184 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits, std::allocator >) + 0xa0 (0x7f46cae290 in /home/yuantian/.local/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__cxx11::basic_string<char, std::char_traits, std::allocator > const&) + 0xb4 (0x7f46cab0fc in /home/yuantian/.local/lib/python3.6/site-packages/torch/lib/libc10.so)
frame #2: at::Context::setQEngine(c10::QEngine) + 0x164 (0x7f5c990c1c in /home/yuantian/.local/lib/python3.6/site-packages/torch/lib/libtorch_cpu.so)
frame #3: THPModule_setQEngine(_object*, _object*) + 0x94 (0x7f60d46a4c in /home/yuantian/.local/lib/python3.6/site-packages/torch/lib/libtorch_python.so)
frame #5: python3() [0x52ba70]
frame #7: python3() [0x529978]
frame #9: python3() [0x5f4d34]
frame #11: python3() [0x5a7228]
frame #12: python3() [0x582308]
frame #16: python3() [0x529978]
frame #17: python3() [0x52b8f4]
frame #19: python3() [0x52b108]
frame #24: __libc_start_main + 0xe0 (0x7f79b09720 in /lib/aarch64-linux-gnu/libc.so.6)
frame #25: python3() [0x420e94]
Aborted (core dumped)
And my system is ubuntu 18, My torch version is 1.8.0, python version is 3.6.9
Do you know why? And thanks for the reply again.
That is strange. This mean pytorch version you have is not compiled with QNNPACK support. @IvanKobzarev, do you know anything about this? Or may be @seemethere do you know whether 1.8 release was built with QNNPACK or not (USE_PYTORCH_QNNPACK).
Thanks for the reply, @kimishpatel . Yeah, I also think it’s so strange, and pls @seemethere and @IvanKobzarev do you know how to solve it? It’s very important to me.
I have set the torch version to 1.7.0 and torchvision to 0.8.1 and have the same problem
QConfig(activation=functools.partial(<class 'torch.quantization.observer.MinMaxObserver'>, reduce_range=True), weight=functools.partial(<class 'torch.quantization.observer.MinMaxObserver'>, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric))
And my platform is Jetson