Hello All;
Here is my issue. I’m running PyTorch model on AWS Studio from Sagemaker.
I manage to sent my tensord and my model and my criterion to cuda(). But GPU seems not to be used., and I don’t know why. I’m running the model in an instance with GPU Tesla 4, which isn’t used as seen in the following snapshot:
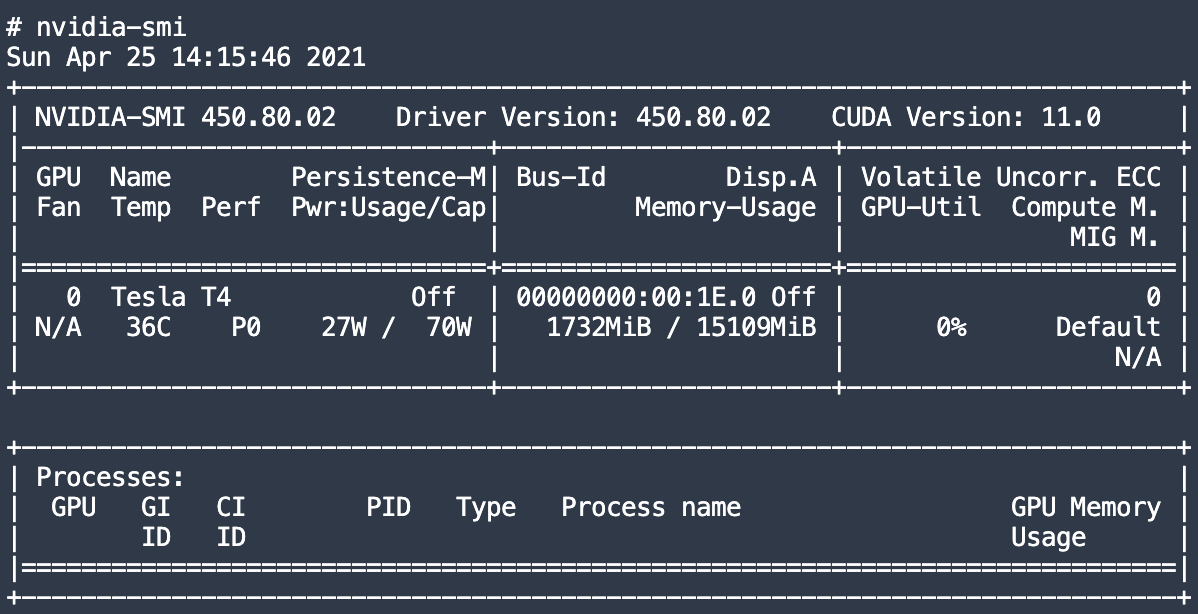
But when I run this code, and I add manually tensors to cuda, with ponctual operations, I can see GPU being consumed:
import torch
a = torch.rand(20000,20000).cuda()
while True:
a += 1
a -= 1
print("Allocated:", round(torch.cuda.memory_allocated(0)/1024**3,1), "GB")
Which is appearing also in nvidia-smi command:
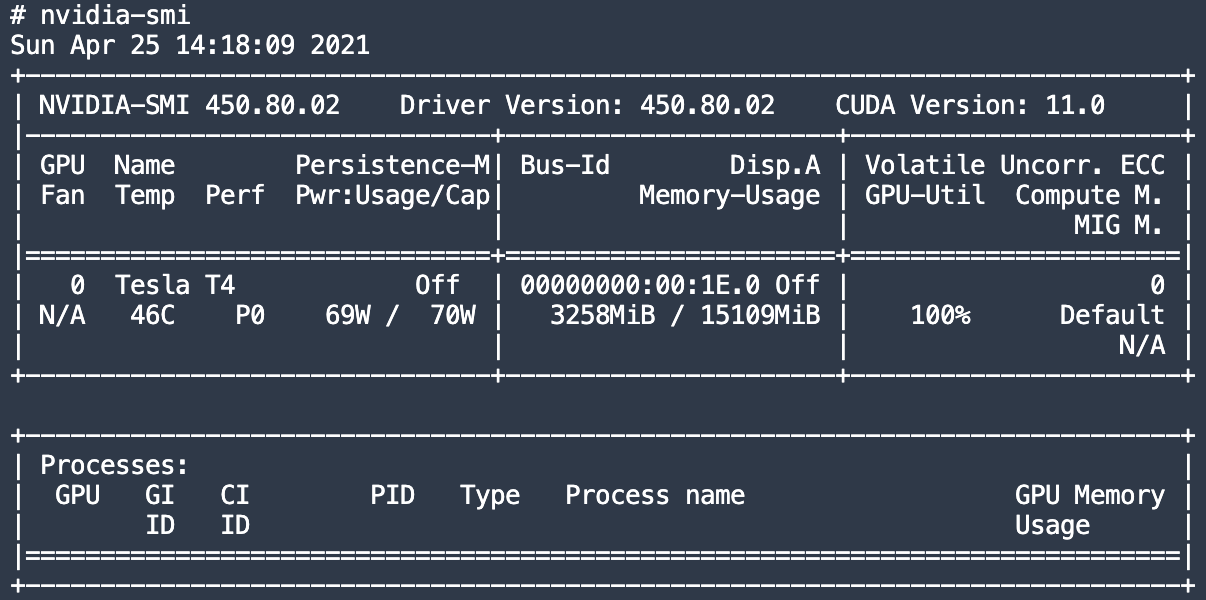
here’s my model:
class Clf(nn.Module):
def __init__(self, params):
super(Clf, self).__init__()
# Input: N x channels_img x 256 x 256
self.pretrained = params['Pretrained']
C_in, C_out, H_in, W_in = params['Input']
self.conv1 = nn.Conv2d(C_in, C_out, kernel_size=3)
self.relu = nn.LeakyReLU(0.2)
self.pool = nn.MaxPool2d(2,2)
h,w,_ = findConv2dOutShape(H_in,W_in,self.conv1,pool=2)
self.conv2 = nn.Conv2d(C_out, C_out * 2, 3)
h,w,_ = findConv2dOutShape(h,w,self.conv2,pool=2)
self.conv3 = nn.Conv2d(C_out * 2, C_out * 4, 3)
h,w,c = findConv2dOutShape(h,w,self.conv3,pool=2)
#self.conv4 = nn.Conv2d(C_out * 4, C_out * 8, 3)
#h,w = findConv2dOutShape(h,w,self.conv4,pool=2)
#self.reshape = Reshape() # => (64, -1)
self.num_flatten = h*w*c
self.fc1 = nn.Linear(self.num_flatten, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
if self.pretrained is None:
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.relu(self.conv3(x))
x = self.pool(x)
#x = self.relu(self.conv4(x))
#x = self.pool(x)
x = x.view(-1, self.num_flatten)
x = self.fc1(x)
x = self.fc2(x)
return torch.sigmoid(x)
And here’s my training loop
def train_model(model, criterion, optimizer, loader, test_loader, num_epoch):
for epoch in range(num_epoch):
print(f'Epoch -- {epoch}')
train_one_epoch(model, loader, optimizer, criterion)
def train_one_epoch(model, loader, optimizer, criterion):
losses = []
longueur_data = 0
for batch_idx, (x, y) in enumerate(loader):
print(f'Batch num -- {batch_idx}')
x = x.cuda()
y = y.to(torch.float32).unsqueeze(1).cuda()
optimizer.zero_grad()
scores= model(x)
loss = criterion(scores, y)
loss.backward()
optimizer.step()
print("Allocated:", round(torch.cuda.memory_allocated(0)/1024**3,1), "GB")
losses.append(loss.item())
longueur_data += x.size(0)
Loss = sum(losses) / longueur_data
print(f'Loss Epoch : {Loss}')
Please help, this is driving crazy since two weeks.
Thank you very much
Habib