I’ve been trying to use Dask to parallelize the computation of trajectories in a reinforcement learning setting, but the cluster doesn’t appear to be releasing the GPU memory, causing it to OOM. I’m working around this problem currently, but I’d love to better understand why this happens. I’ve reduced the problem to a simpler test case:
import multiprocessing as mp
import torch
import torch.nn
import torch.optim
import itertools
import time
from typing import Tuple
big_number = 10000
class HugeModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.lin1 = torch.nn.Linear(big_number, big_number)
self.lin2 = torch.nn.Linear(big_number, 1)
def forward(self, t1: torch.Tensor):
return self.lin2(self.lin1(t1))
def create_huge_model():
huge_model = HugeModel()
training_x = torch.randn(10, big_number)
training_y = torch.sum(training_x, dim=-1)
optimizer = torch.optim.Adam(huge_model.parameters())
for i in range(4):
optimizer.zero_grad()
loss = torch.nn.SmoothL1Loss()(huge_model(training_x).squeeze(dim=-1), training_y)
print(f'Training... Iteration {i}: {loss.item()}')
loss.backward()
optimizer.step()
return huge_model
def do_some_inference(tup: Tuple[torch.nn.Module, torch.Tensor]):
with torch.no_grad():
model, batch = tup
result = model(batch).cpu().numpy()
del tup
del model
del batch
clean_up_the_pool()
return result
def clean_up_the_pool(*args, **kwargs):
if torch.cuda.is_available():
torch.cuda.empty_cache()
if __name__ == '__main__':
pool_size = 40
mp.set_start_method('spawn')
pool = mp.Pool(pool_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
big_model = create_huge_model().to(device)
with torch.no_grad():
batches = torch.randn(2, big_number).to(device)
batches_list = [batches[i:i+1, :] for i in range(2)]
for i in range(30):
work = zip(itertools.repeat(big_model), batches_list)
print("Doing some inference with multiprocessing...")
results = pool.map(do_some_inference, work)
print("Waiting...")
time.sleep(5)
print("Cleaning up")
pool.map(clean_up_the_pool, range(pool_size * 4))
print("Waiting...")
time.sleep(5)
pool.close()
Essentially, if I create a large pool (40 processes in this example), and 40 copies of the model won’t fit into the GPU, it will run out of memory, even if I’m computing only a few inferences (2) at a time. nvidia-smi shows that even after the pool.map completes, the process still retains its allocation of around 500 MB of GPU memory, even though I’ve tried my best to clear it with torch.cuda.empty_cache(). This results in an OOM error when another process in the pool tries to get its slice of the GPU.
nvidia-smi starts filling up with these processes that aren’t actually doing anything, but taking up memory:
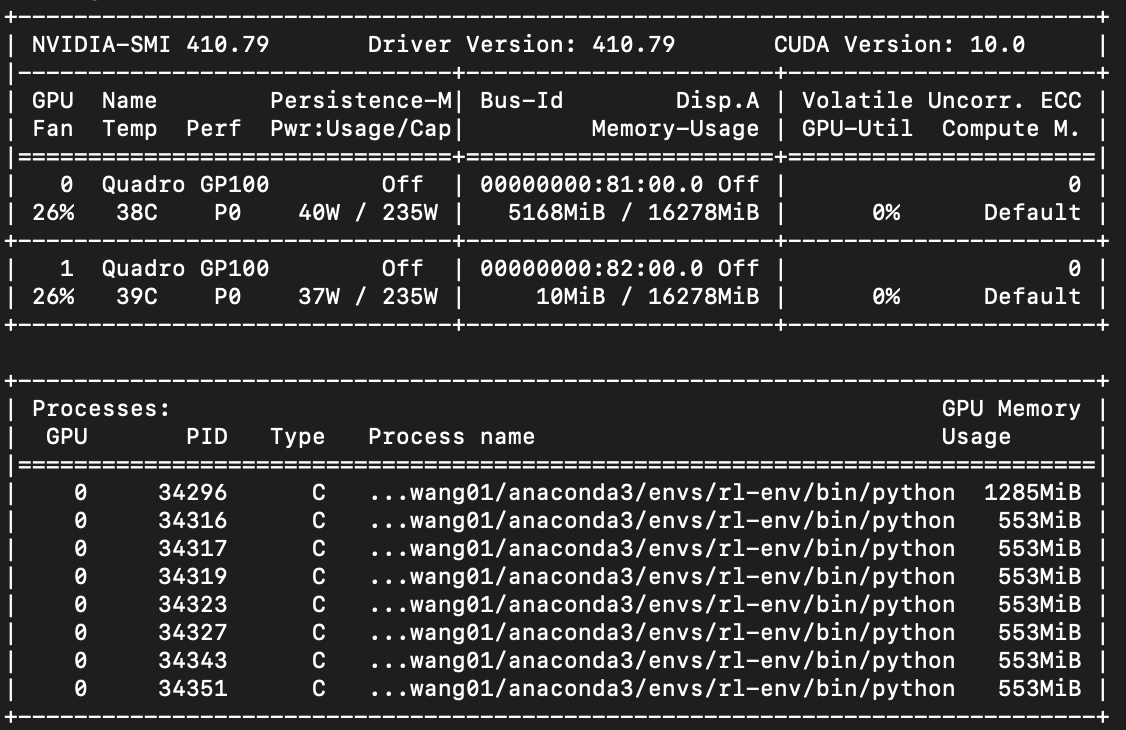
Is there any way, short of closing the pool, to get PyTorch to release the memory that it doesn’t need anymore, at least until it gets a task from pool.map?
I don’t want to close the pool, because I’ve had problems with launching a Dask LocalCluster after messing around with CUDA in the parent process. Closing and re-opening a pool also seems hacky.
