Hello,
I’m having issues getting pytorch to recognize my GPU as whenever I run “torch.cuda.is_available()”, it says the CUDA driver failed to initialize.
Pytorch is installed using pip and I have tried reinstalling different versions of the NVIDIA driver / CUDA toolkit and pytorch version but I always get the same error.
Any help would be appreciated.
Here is the output from nvidia-smi:
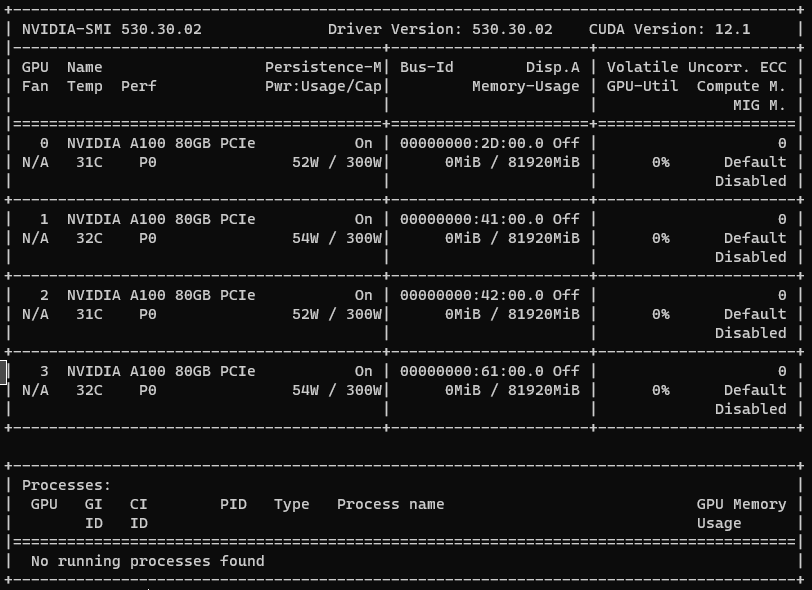
Here is the output from nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
Here is the output from torch envirionment:
PyTorch version: 2.1.2+cu121
Is debug build: False
CUDA used to build PyTorch: 12.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-91-generic-x86_64-with-glibc2.35
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
GPU 2: NVIDIA A100 80GB PCIe
GPU 3: NVIDIA A100 80GB PCIe
Nvidia driver version: 530.30.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: AuthenticAMD
Model name: AMD Ryzen Threadripper PRO 3975WX 32-Cores
CPU family: 23
Model: 49
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
Stepping: 0
Frequency boost: enabled
CPU max MHz: 4368.1641
CPU min MHz: 2200.0000
BogoMIPS: 6986.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd amd_ppin arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sme sev sev_es
Virtualization: AMD-V
L1d cache: 1 MiB (32 instances)
L1i cache: 1 MiB (32 instances)
L2 cache: 16 MiB (32 instances)
L3 cache: 128 MiB (8 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-63
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec rstack overflow: Mitigation; safe RET
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==2.1.2
[pip3] torchaudio==2.1.2
[pip3] torchvision==0.16.2
[pip3] triton==2.1.0
[conda] Could not collect
