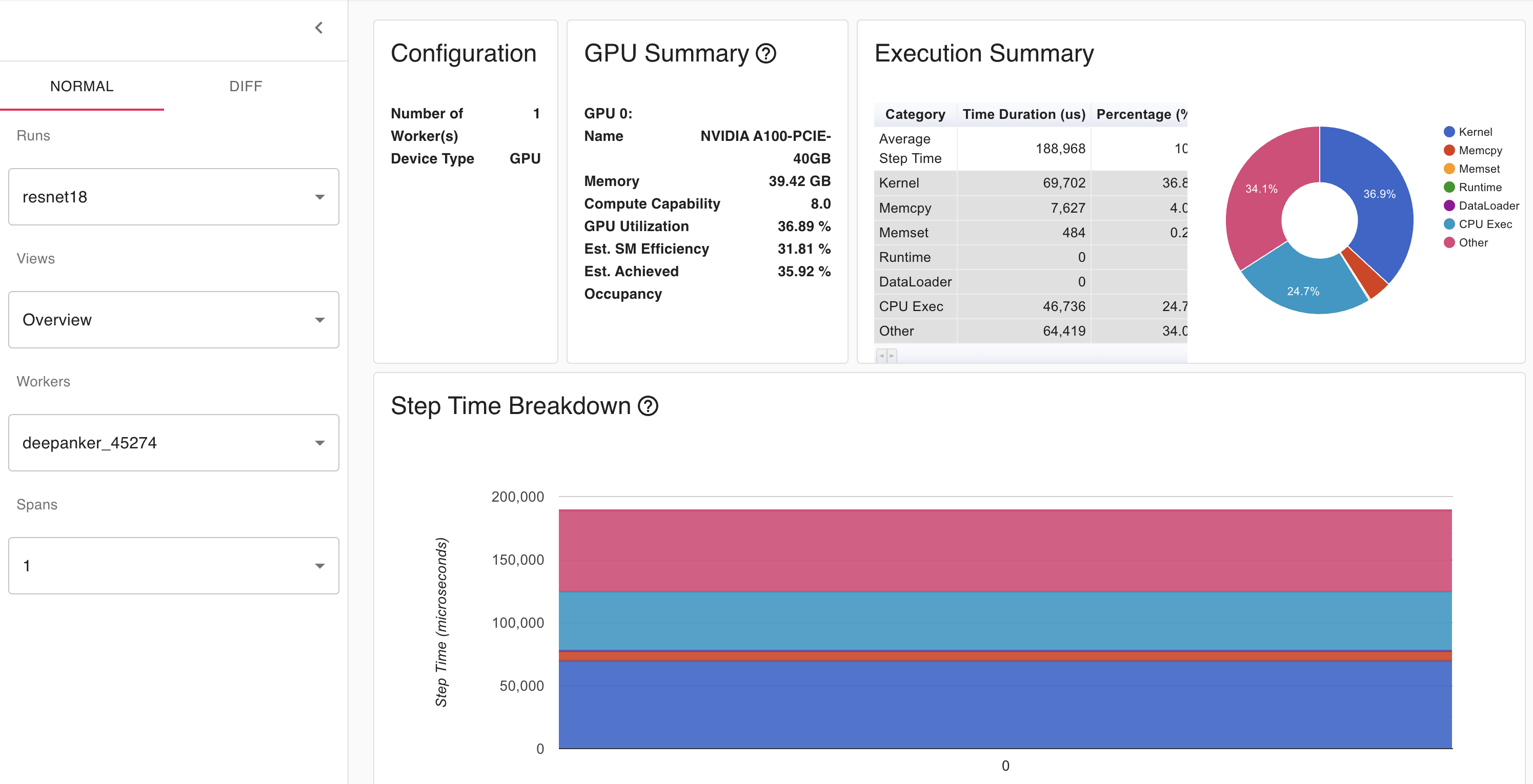
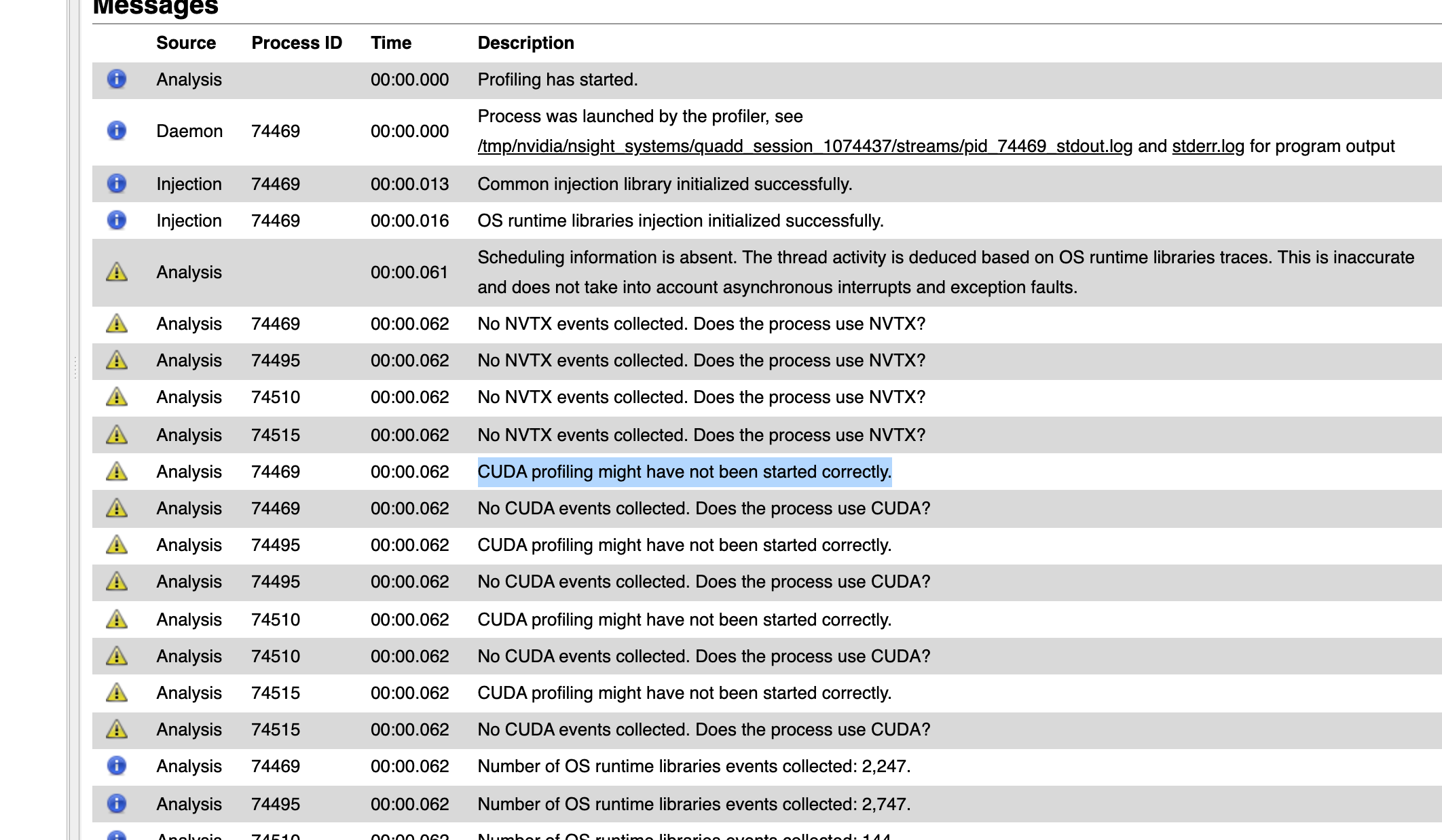
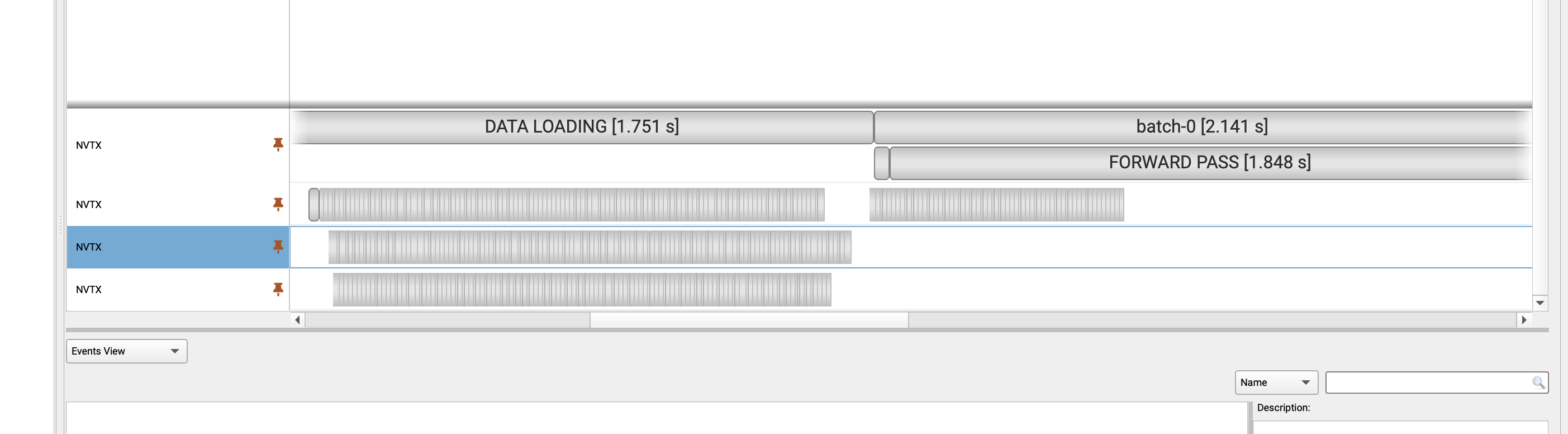
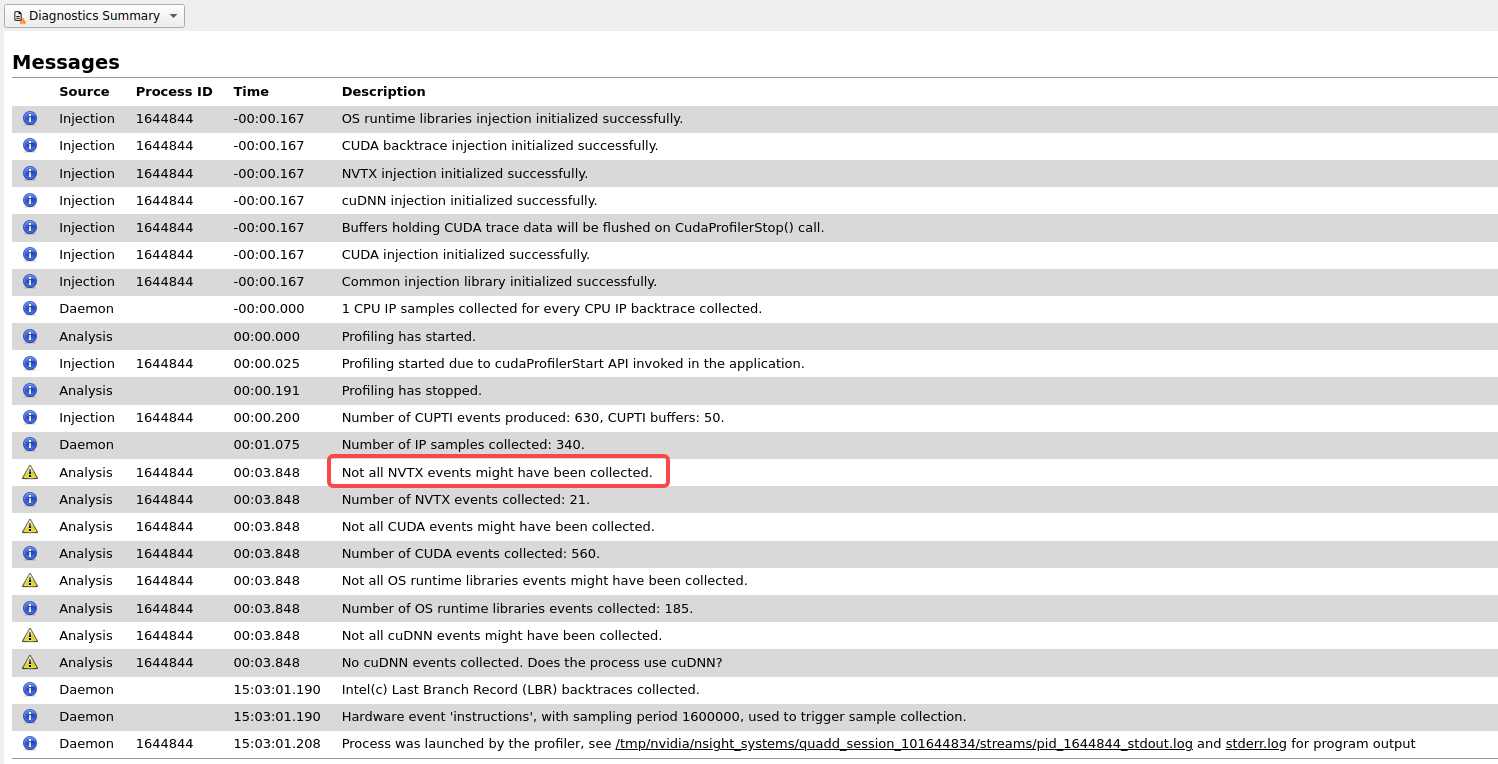
Could you give me some advices to show the ''DATA LOADING"? I tried pytorch 1.10和1.13, both didn’t work. Below is my environment and test code.
>>> nsys status -e
Timestamp counter supported: Yes
Sampling Environment Check
Linux Kernel Paranoid Level = 1: OK
Linux Distribution = Ubuntu
Linux Kernel Version = 5.14.0-1056-oem: OK
Linux perf_event_open syscall available: OK
Sampling trigger event available: OK
Intel(c) Last Branch Record support: Available
Sampling Environment: OK
import os
import torch
import nvtx
import time
from torch import nn
from torch.optim import SGD
from torch.utils.data import Dataset, DataLoader, DistributedSampler
class TestDataset(Dataset):
def __init__(self) -> None:
self.x = torch.randn(num_samples, 10)
self.y = torch.randn(num_samples, 1)
# @nvtx.annotate("data loading",color='yellow')
def __getitem__(self, index):
torch.cuda.nvtx.range_push("data loading")
x = self.x[index]
y = self.y[index]
time.sleep(0.1)
torch.cuda.nvtx.range_pop()
return x,y
def __len__(self):
return num_samples
class Model(nn.Module):
def __init__(self) -> None:
super(Model, self).__init__()
self.classifer = nn.Linear(10, 3)
self.pred = nn.Linear(10, 3)
# @nvtx.annotate("forward",color='blue')
def forward(self, x):
pred = self.pred(x)
classifier_out = self.classifer(x)
classifer_score = torch.softmax(classifier_out, dim=1)
_, index = torch.max(classifer_score, dim=1)
return pred[torch.arange(index.shape[0]), index]
@nvtx.annotate("train",color='red')
def train():
model = Model().to(device)
optimizer = SGD(model.parameters(), 0.1)
loss_fn = nn.MSELoss()
dataset = TestDataset()
# train_sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, batch_size = batch_size, num_workers = 2, sampler=None)#,sampler=train_sampler
for epoch in range(1):
for batch, (x, y) in enumerate(dataloader):
if batch == 1: torch.cuda.cudart().cudaProfilerStart()
if batch >= 1: torch.cuda.nvtx.range_push("iteration{}".format(batch))
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
if batch >= 1: torch.cuda.nvtx.range_push("forward")
output = model(x)
if batch >= 1: torch.cuda.nvtx.range_pop()
loss = loss_fn(output, y)
if batch >= 1: torch.cuda.nvtx.range_push("backward")
loss.backward()
if batch >= 1: torch.cuda.nvtx.range_pop()
if batch >= 1: torch.cuda.nvtx.range_push("opt.step()")
optimizer.step()
if batch >= 1: torch.cuda.nvtx.range_pop()
# print('pred.bias:', model.state_dict()['pred.bias'])
print('classifer.bias:', model.state_dict()['classifer.bias'])
if batch >= 1: torch.cuda.nvtx.range_pop()# iteration
torch.cuda.cudart().cudaProfilerStop()
if __name__ == "__main__":
os.environ['CUDA_LAUNCH_BLOCKING']='1'
batch_size = 4
num_samples = 20
device = torch.device('cuda')
train()
Run code:
nsys profile -w true -t cuda,nvtx,osrt,cudnn,cublas -s cpu --force-overwrite=true --capture-range=cudaProfilerApi --capture-range-end=stop-shutdown --cudabacktrace=true -x true --output=quickstart python test_nsys.py