Hello!
I have a question about simulation of a network by Pytorch.
This is the network that I want o simulate:
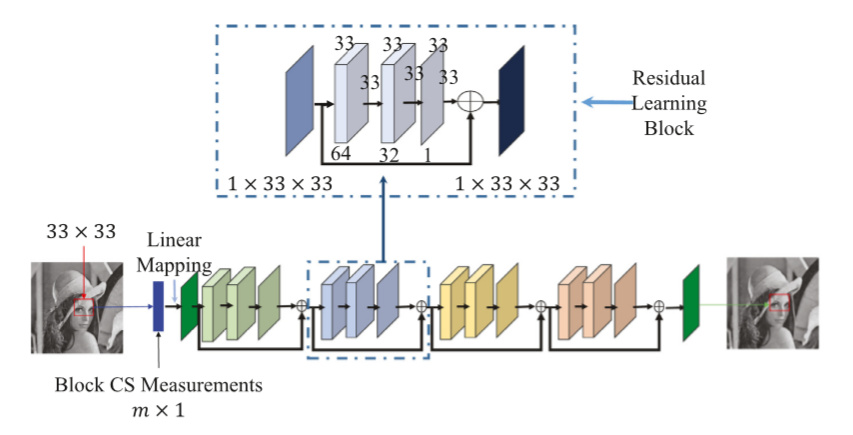
and I wrote it’s code:
class ResidualLearningNet(nn.Module):
def __init__(self):
super(ResidualLearningNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, padding=5),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=1, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=7, padding=3)
)
self.conv4 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, padding=5),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv5 = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=1, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
)
self.conv6 = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=7, padding=3)
)
self.conv7 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, padding=5),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv8 = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=1, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
)
self.conv9 = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=7, padding=3)
)
self.conv10 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=11, padding=5),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.conv11 = nn.Sequential(
nn.Conv2d(64, 32, kernel_size=1, padding=0),
nn.BatchNorm2d(32),
nn.ReLU(),
)
self.conv12 = nn.Sequential(
nn.Conv2d(32, 1, kernel_size=7, padding=3)
)
def forward(self, x):
identify1=x
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = out + identify1
identify2=out
out = self.conv4(out)
out = self.conv5(out)
out = self.conv6(out)
out = out + identify2
identify3=out
out = self.conv7(out)
out = self.conv8(out)
out = self.conv9(out)
out = out + identify3
identify4=out
out = self.conv10(out)
out = self.conv11(out)
out = self.conv12(out)
out = out + identify4
return out
is it wrong?
It’s loss backward time takes hours.
Would you mind helping me with fixing my problems,please.



