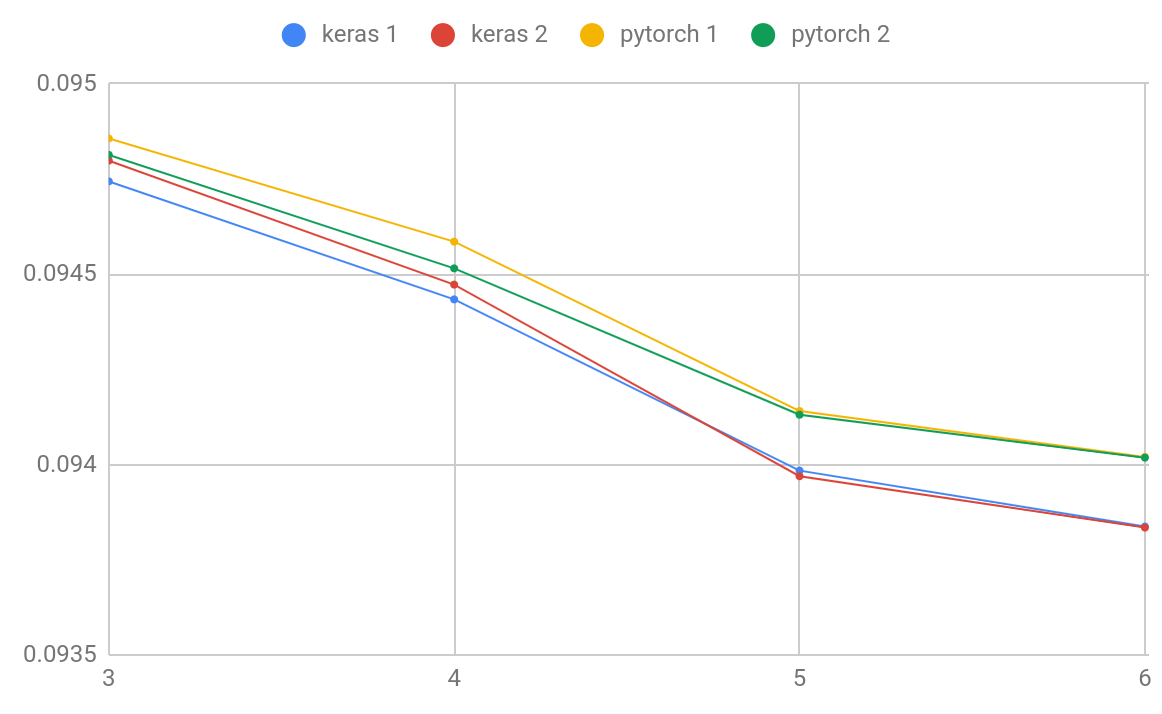
I’m working on Kaggle Quora challenge. PyTorch proves to be a little faster than Keras and that’s why I want to use it instead of Keras. But the results are slightly worse than in Keras, not much in absolute terms, but enough. The results are repeatable and I am sure that it’s real. For the past week I’ve been trying to replicate the Keras result and I’m coming closer but I’m still a bit off. The final ensemble is made up of 6 models. The metric is log loss, and it’s calculated over 10 stratified folds created with the same seed.
The results are:
PyTorch 1 0.09402009289
PyTorch 2 0.09401799725
Keras 1 0.09383706382
Keras 2 0.09385460710
I load the data with identical functions and I initialize the Pytorch weights using this function, minus the embed.weight part. I use the same batch_size and every other variable I can thik of.
Keras sample model
inp = Input(shape=(maxlen,))
x = Embedding(max_features, embed_size, weights=[embedding_matrix])(inp)
x = Bidirectional(CuDNNGRU(128, return_sequences=True))(x)
x = Bidirectional(CuDNNGRU(64, return_sequences=True))(x)
x = GlobalMaxPooling1D()(x)
x = Dense(1, activation="sigmoid")(x)
model = Model(inputs=inp, outputs=x)
optimizer = Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0)
model.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
model.fit(train_X, train_y, batch_size=192, epochs=3)
Pytorch same model:
train_loader = torch.utils.data.DataLoader(train, batch_size=192, shuffle=True)
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
hidden_size1 = 128
hidden_size2 = 64
self.embedding = nn.Embedding(max_features, embed_size)
self.embedding.weight = nn.Parameter(torch.tensor(embedding_matrix, dtype=torch.float32))
self.embedding.weight.requires_grad = True
self.gru1 = nn.GRU(embed_size, hidden_size1, bidirectional=True, batch_first=True)
self.gru2 = nn.GRU(hidden_size1*2, hidden_size2, bidirectional=True, batch_first=True)
self.out = nn.Linear(hidden_size2*2, 1)
def forward(self, x):
h_embedding = self.embedding(x)
h_gru1, _ = self.gru1(h_embedding)
h_gru2, _ = self.gru2(h_gru1)
max_pool, _ = torch.max(h_gru2, 1)
out = self.out(max_pool)
out = torch.sigmoid(out)
return out
model = NeuralNet()
model.apply(init_weights)
model.cuda()
loss_fn = torch.nn.BCELoss()
optimizer = torch.optim.Adamax(model.parameters())
torch.cuda.seed_all()
for epoch in range(3):
torch.cuda.seed_all()
model.train()
avg_loss = 0.
for x_batch, y_batch in train_loader:
y_pred = model(x_batch)
loss = loss_fn(y_pred, y_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss += loss.item() / len(train_loader)