Hi, I’m a begginer in PyTorch and I’m running into a problem with CUDA.
I want to finetune a MobileNetV3 to a Binary classification and the script seems to be OK, it shows that the cuda is available and the device is set to ‘cuda’ for all inputs, targets and models, but it seems that the GPU is not being used.
Now, it took +40min to train one epoch, and I know that it can be done in ~3min, because yesterday (02/22/2024) I was able to run it in the GPU, after install CUDA Toolkit 12.3 manually and update the nvidia drivers to 545, and that was what it took to train one epoch.
But today, after rebooting my PC the GPU stopped being used.
I already uninstalled and installed Pytorch 2.2.1 with cuda121 but it’s still not working.
For now, I cleaned my PC and left just PyTorch 2.2.1+cuda121 installed, but it’s still not working.
When the script is running, I can see the memory being allocated in the GPU (watch nvidia-smi) but it seems that it isn’t processing the images there.
I’m running the script in a Python notebook, using Linux mint 21.3, here are some details about my pc and the code.
My pc:
Operating System: Linux-x86_64 (MInt 21.3)
NVIDIA Driver Version: 545.29.06
NVML Version: 12.545.29.06
GPU 0 : NVIDIA GeForce GTX 1660 SUPER
CPU: Intel i5-9400F (6) @ 4.100GHz
RAM: 16GB
Code (Verify CUDA Available):
print(f"PyTorch version: {torch.__version__}")
print("--------------------------------------------------")
print(f"Using cuda: {torch.cuda.is_available()}")
print(f"Cuda corrent device: {torch.cuda.current_device()}")
print(f"Cuda device: {torch.cuda.get_device_name(torch.cuda.current_device())}")
print(f"Torch Backend enable: {torch.backends.cudnn.enabled}")
print(f"Torch Backend: {torch.backends.cudnn.version() }")
-----------------------------------------------------------------------------------------------------------------
PyTorch version: 2.2.1+cu121
--------------------------------------------------
Using cuda: True
Cuda corrent device: 0
Cuda device: NVIDIA GeForce GTX 1660 SUPER
Torch Backend enable: True
Torch Backend: 8902
Code (Inputs, targets, labels and model in GPU):
NUM_EPOCHS = 1
for epoch in range(NUM_EPOCHS):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
preds = model(inputs).squeeze(1)
loss = bce_loss(preds, labels.float())
loss.backward()
optimizer.step()
print(f"inputs device: {inputs.device}, labels device: {labels.device}, model device: {next(model.parameters()).device}, preds: {preds.device}, model: {next(model.parameters()).device}")
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train)
print(f"Epoch [{epoch + 1}/{NUM_EPOCHS}], Training Loss: {epoch_loss:.4f}")
Print return:
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
inputs device: cuda:0, labels device: cuda:0, model device: cuda:0, preds: cuda:0, model: cuda:0
...
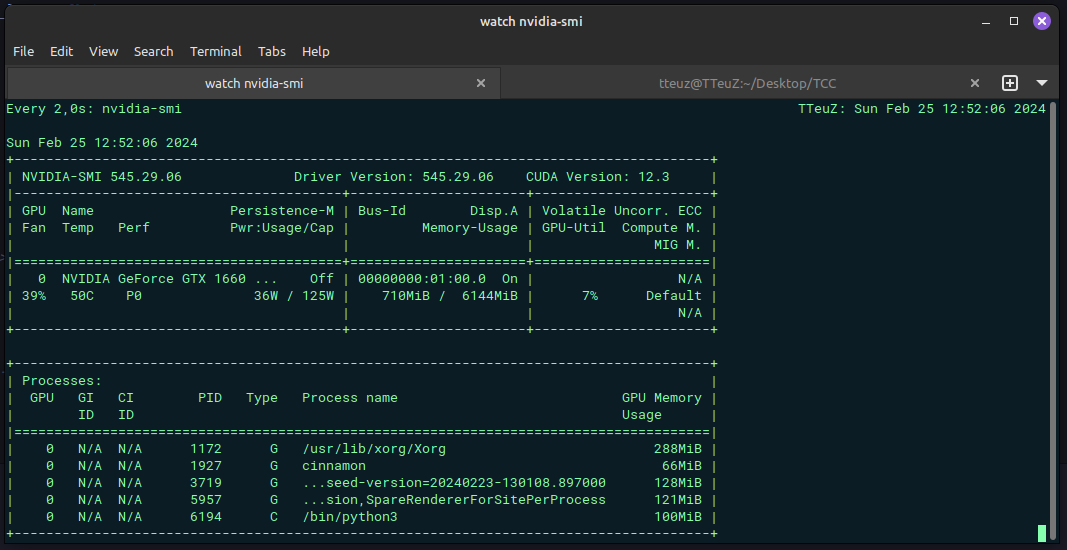
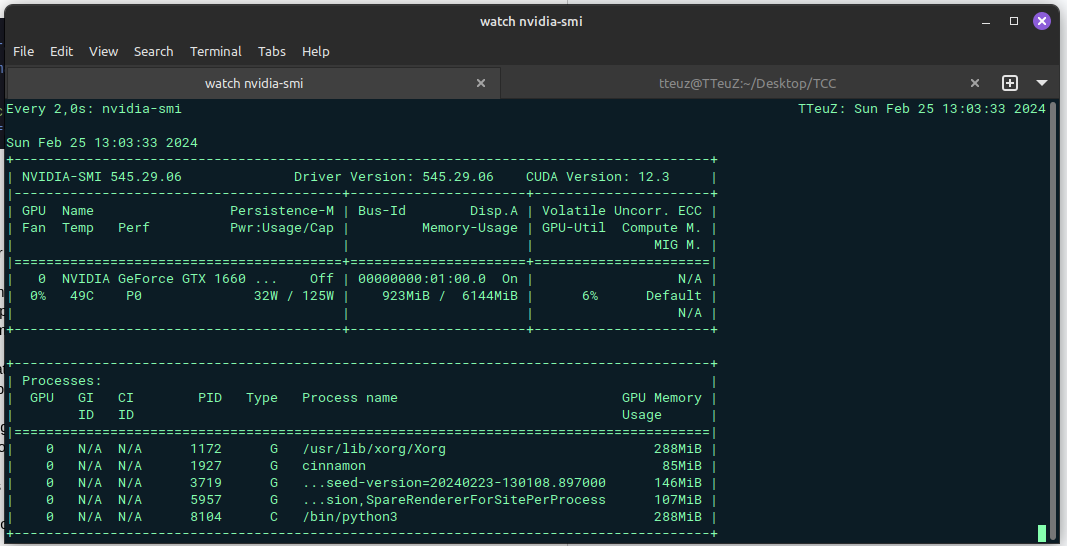
nvidia-smi with script running:
We can verify that the python allocated memory in the GPU, but the GPU is not being used for processing. As i said, yesterday (02/22/2024) when the GPU was entirely used, the GPU use stayed near to 100% and the power usage near to 125w.

Full code:
import torch
from torchvision.models import mobilenet_v3_large as mobilenet
from torchvision.models import MobileNet_V3_Large_Weights as pre_weights
from sklearn.metrics import confusion_matrix, accuracy_score
import helpers.data_handler as data_handler
import helpers.utils as utils
print(f"PyTorch version: {torch.__version__}")
print("--------------------------------------------------")
print(f"Using cuda: {torch.cuda.is_available()}")
print(f"Cuda corrent device: {torch.cuda.current_device()}")
print(f"Cuda device: {torch.cuda.get_device_name(torch.cuda.current_device())}")
print(f"Torch Backend enable: {torch.backends.cudnn.enabled}")
print(f"Torch Backend: {torch.backends.cudnn.version() }")
NUM_CLASSES = 1
train, validation, test = data_handler.get_datasets()
print(f"Train dataset size: {len(train)}")
print(f"validation dataset size: {len(validation)}")
print(f"test dataset size: {len(test)}")
train_loader = torch.utils.data.DataLoader(train, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
val_loader = torch.utils.data.DataLoader(validation, batch_size=1500, shuffle=False, num_workers=4, pin_memory=True)
test_loader = torch.utils.data.DataLoader(test, batch_size=1500, shuffle=False, num_workers=4, pin_memory=True)
model = mobilenet(weights=pre_weights.IMAGENET1K_V2)
model.classifier[-1] = torch.nn.Linear(1280, NUM_CLASSES)
bce_loss = torch.nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
print(model.classifier)
print(f"is in cuda: {next(model.parameters()).is_cuda}")
print(f"device: {device}")
NUM_EPOCHS = 1
for epoch in range(NUM_EPOCHS):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
preds = model(inputs).squeeze(1)
loss = bce_loss(preds, labels.float())
loss.backward()
optimizer.step()
print(f"inputs device: {inputs.device}, labels device: {labels.device}, model device: {next(model.parameters()).device}, preds: {preds.device}, model: {next(model.parameters()).device}")
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(train)
print(f"Epoch [{epoch + 1}/{NUM_EPOCHS}], Training Loss: {epoch_loss:.4f}")
# Validation
model.eval()
val_labels = []
val_preds = []
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
preds = model(inputs)
val_labels.extend(labels.cpu().numpy())
val_preds.extend((torch.sigmoid(preds) > 0.5).cpu().numpy().astype(int))
accuracy = accuracy_score(val_labels, val_preds)
cm = confusion_matrix(val_labels, val_preds)
print(f'Validation Accuracy: {accuracy:.2f}%')
utils.print_confusion_matrix(cm)
# Test
model.eval()
test_labels = []
test_preds = []
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
preds = model(inputs)
test_labels.extend(labels.cpu().numpy())
test_preds.extend((torch.sigmoid(preds) > 0.5).cpu().numpy().astype(int))
accuracy = accuracy_score(test_labels, test_preds)
cm = confusion_matrix(test_labels, test_preds)
print(f'Test Accuracy: {accuracy:.2f}%')
utils.print_confusion_matrix(cm)
Do you guys know what I can do to make it use GPU correctly?