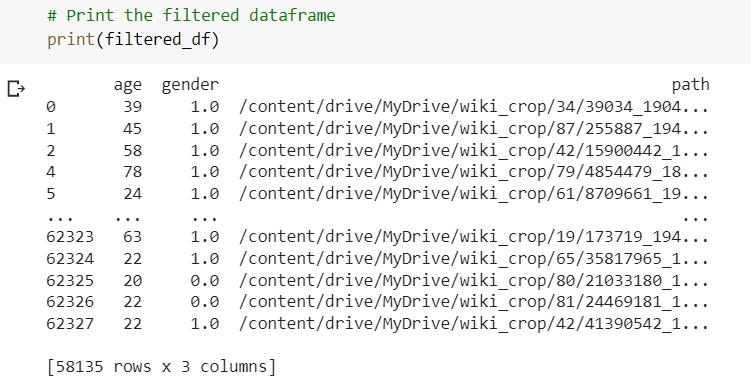
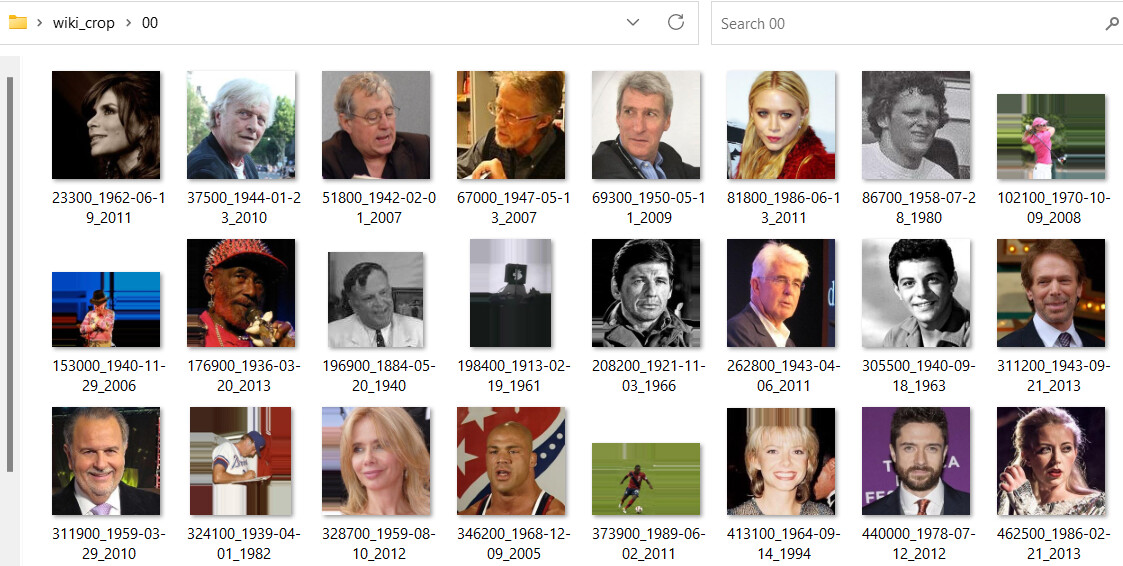
Tried to load training data with PyTorch torch.datasets.ImageFolder in Colab. I am using Wiki crop data for age and gender prediction.
I am try to fix this error but I couldn’t.
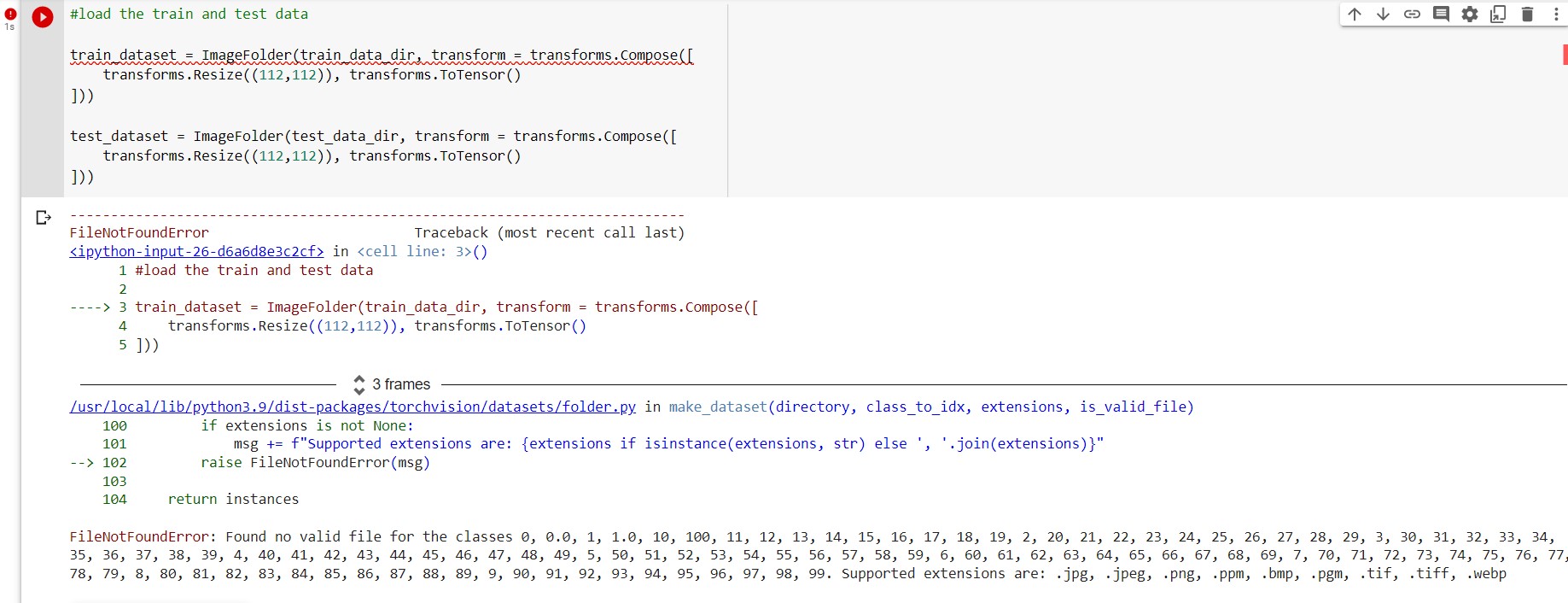
I have uploaded my code here,
‘’’
WikiCrop_df = pd.read_csv('/content/drive/MyDrive/wiki_crop/wikiCrop.csv')
#Define the path to the directory containing the images
src_folder = '/content/drive/MyDrive/wiki_crop/'
# Define the path to the train directory
train_dir = '/content/drive/MyDrive/WikiCrop_TrainDirData'
# Define the path to the test directory
test_dir = '/content/drive/MyDrive/WikiCrop_TestDirData'
import os
# Create the train and test directories
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
#Now, we can create subdirectories in the train and test directories for each label using age and gender information in your data frame:
for age in filtered_df.age.unique():
os.mkdir(os.path.join(train_dir, str(age)))
os.mkdir(os.path.join(test_dir, str(age)))
for gender in filtered_df.gender.unique():
os.mkdir(os.path.join(train_dir, str(gender)))
os.mkdir(os.path.join(test_dir, str(gender)))
# Split the data frame into train and test sets, with a specified ratio (e.g., 80/20):
train_ratio = 0.8
train_df = WikiCrop_df.sample(frac=train_ratio, random_state=42)
test_df = WikiCrop_df.drop(train_df.index)
# Create the train and test directories
if not os.path.exists(train_dir):
os.makedirs(train_dir)
if not os.path.exists(test_dir):
os.makedirs(test_dir)
for index, row in train_df.iterrows():
src_path = os.path.join(src_folder, row['path'])
dst_path = os.path.join(train_dir, str(row['age']), str(row['gender']), str(row['path']))
if src_path != dst_path:
try:
copyfile(src_path, dst_path)
except FileExistsError as e:
print(f"Error copying {src_path} to {dst_path}: {e}")
for index, row in test_df.iterrows():
src_path = os.path.join(src_folder, row['path'])
dst_path = os.path.join(test_dir, str(row['age']), str(row['gender']), str(row['path']))
if src_path != dst_path:
try:
copyfile(src_path, dst_path)
except FileExistsError:
pass
#train and test data directory
train_data_dir = '/content/drive/MyDrive/WikiCrop_TrainDirData'
test_data_dir = '/content/drive/MyDrive/WikiCrop_TestDirData'
import torch
import torchvision
from torchvision import transforms
from torchvision.datasets import ImageFolder
#load the train and test data
train_dataset = ImageFolder(train_data_dir, transform = transforms.Compose([
transforms.Resize((112,112)), transforms.ToTensor()
]))
test_dataset = ImageFolder(test_data_dir, transform = transforms.Compose([
transforms.Resize((112,112)), transforms.ToTensor()
]))
Please tell me where my code is wrong. I tried to fix this error since long time but I couldn’t. I have uploaded how my WikiCrop_TrainDirData looks like.

Thank you in advance.