Is there any way to do real time image classification with webcam using Pytorch trained model?
You could just grab the webcam frame, preprocess it accordingly to your pipeline, and feed it into your model.
I’ve created a small example some time ago using PyGame and OpenCV: link.
2 Likes
Do all the frames in the video need to be classified? For the classification process, I need to pre-process the image in many ways : Resizing, PIL image, ToTensor, unsqueeze, and GPU Tensor so isn’t it going to affect the performance too much? I am using Resnet-50 model for ASL sign language classifier.
The frames won’t be buffered, so that you will lose some frames while your processing is performed.
In my example code there is also a FPS counter showing the current frame rate.
I did the same pre-processing for individual frames as I do to the single image classification but it still keeps getting ‘nan’ for the result. I tried to classify one image per 4 frames. Here is the code!
import numpy as np
import torch
import torch.nn
import torchvision
from torch.autograd import Variable
from torchvision import transforms
import PIL
import cv2
#This is the Label
Labels = { 0 : 'A',
1 : 'B',
2 : 'C',
3 : 'D',
4 : 'E',
5 : 'F',
6 : 'G',
7 : 'H',
8 : 'I',
9 : 'K',
10: 'L',
11: 'M',
12: 'N',
13: 'O',
14: 'P',
15: 'Q',
16: 'R',
17: 'S',
18: 'T',
19: 'U',
20: 'V',
21: 'W',
22: 'X',
23: 'Y'
}
# Let's preprocess the inputted frame
data_transforms = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0,0.225])
]
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") ##Assigning the Device which will do the calculation
model = torch.load("Resnet50_Left_Pretrained_ver1.1.pth") #Load model to CPU
model = model.to(device) #set where to run the model and matrix calculation
model.eval() #set the device to eval() mode for testing
#Set the Webcam
def Webcam_720p():
cap.set(3,1280)
cap.set(4,720)
def argmax(prediction):
prediction = prediction.cpu()
prediction = prediction.detach().numpy()
top_1 = np.argmax(prediction, axis=1)
score = np.amax(prediction)
score = '{:6f}'.format(score)
prediction = top_1[0]
result = Labels[prediction]
return result,score
def preprocess(image):
image = PIL.Image.fromarray(image) #Webcam frames are numpy array format
#Therefore transform back to PIL image
print(image)
image = data_transforms(image)
image = image.float()
#image = Variable(image, requires_autograd=True)
image = image.cuda()
image = image.unsqueeze(0) #I don't know for sure but Resnet-50 model seems to only
#accpets 4-D Vector Tensor so we need to squeeze another
return image #dimension out of our 3-D vector Tensor
#Let's start the real-time classification process!
cap = cv2.VideoCapture(0) #Set the webcam
Webcam_720p()
fps = 0
show_score = 0
show_res = 'Nothing'
sequence = 0
while True:
ret, frame = cap.read() #Capture each frame
if fps == 4:
image = frame[100:450,150:570]
image_data = preprocess(image)
print(image_data)
prediction = model(image_data)
result,score = argmax(prediction)
fps = 0
if result >= 0.5:
show_res = result
show_score= score
else:
show_res = "Nothing"
show_score = score
fps += 1
cv2.putText(frame, '%s' %(show_res),(950,250), cv2.FONT_HERSHEY_SIMPLEX, 2, (255,255,255), 3)
cv2.putText(frame, '(score = %.5f)' %(show_score), (950,300), cv2.FONT_HERSHEY_SIMPLEX, 1,(255,255,255),2)
cv2.rectangle(frame,(400,150),(900,550), (250,0,0), 2)
cv2.imshow("ASL SIGN DETECTER", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyWindow("ASL SIGN DETECTER")
1 Like
Is your code working “offline”, i.e. without the webcam just using a single image?
Yes. It works on single image classification.
Is it showing 'Nothing' or really 'nan'?
In your code, result seems to be the the most likely character as a string.
However, you are comparing it to a float threshold:
if result >= 0.5:
...
This should yield an error like TypeError: '>=' not supported between instances of 'str' and 'float'.
Somehow your code still seems to run. Could you check this issue?
Sorry. It was my mistake. Actually, I was referring to the score being ‘nan’.The result is clearly an char (from the Labels). I checked the tensors outputted from data_ transforms. The Tensors is having (-inf) values in it.
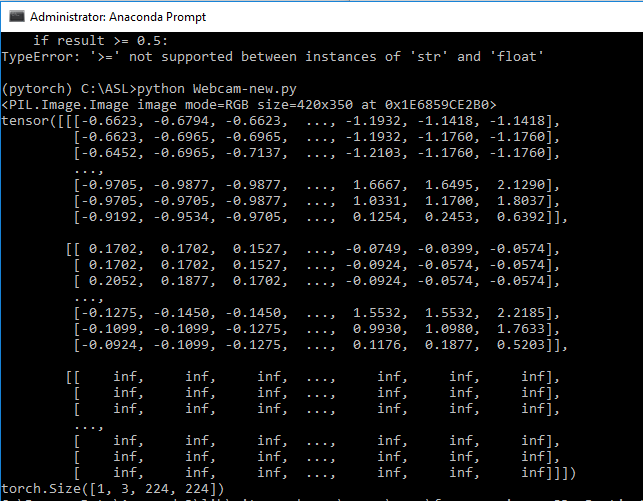
OK, I see.
Then try to debug, why your image capture/pre-processing is returning nans.
I would check the frame returned by cap.read() first and check all following procedures for nans.
1 Like
I’ve checked another possibility and this is most likely the issue.
In your normalization, you have an additional zero for the third channel, which results in the inf values:
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0,0.225])
Remove the zero and try it again.
1 Like
Thank you very much, Patrick! Yes, the extra normalization value was causing the ‘nan’. Since the tensor are having ‘nan’ values, the scores also become ‘nan’ values since the model can’t properly feed forward with nan values.So the scores becomes messed up! Now, the real-time ASL SignLanguage Classifier is working perfectly!
1 Like