First off, I am a newbie to PyTorch as I was mostly using Tensorflow/Keras in the past. So, I would be happy if someone can point out any obvious mistake here. I downloaded the IMDB sentiment classification data from Kaggle. I built similar sentiment classification model using both Tensorflow and PyTorch. Before I fixed the initializations for my PyTorch model to match the initialization scheme used by Tensorflow, the results from my PyTorch model was substantially worse compared to my Tensorflow model.
Question: Is this expected and does it mean the initialization scheme of Tensorflow is better in some cases? Should we always try different initialization methods given the impact that could be potentially large?
Here are the results:
1. PyTorch with default initialization
Epoch 1/10 - train_loss: 0.6928 train_acc: 50.9% val_loss: 0.6917 val_acc: 53.2%
Epoch 2/10 - train_loss: 0.6906 train_acc: 54.0% val_loss: 0.6898 val_acc: 55.2%
Epoch 3/10 - train_loss: 0.6881 train_acc: 55.6% val_loss: 0.6870 val_acc: 56.1%
Epoch 4/10 - train_loss: 0.6843 train_acc: 56.5% val_loss: 0.6822 val_acc: 57.2%
Epoch 5/10 - train_loss: 0.6789 train_acc: 57.9% val_loss: 0.6758 val_acc: 58.0%
Epoch 6/10 - train_loss: 0.6682 train_acc: 59.9% val_loss: 0.6552 val_acc: 61.6%
Epoch 7/10 - train_loss: 0.6368 train_acc: 64.2% val_loss: 0.6358 val_acc: 63.4%
Epoch 8/10 - train_loss: 0.6037 train_acc: 68.0% val_loss: 0.5881 val_acc: 69.1%
Epoch 9/10 - train_loss: 0.5778 train_acc: 70.4% val_loss: 0.5622 val_acc: 71.7%
Epoch 10/10 - train_loss: 0.5493 train_acc: 72.8% val_loss: 0.5423 val_acc: 72.5%
2. PyTorch with Keras initialization for LSTM and FC layers
Epoch 1/10 - train_loss: 0.6942 train_acc: 51.8% val_loss: 0.6872 val_acc: 54.3%
Epoch 2/10 - train_loss: 0.6838 train_acc: 55.2% val_loss: 0.6800 val_acc: 57.2%
Epoch 3/10 - train_loss: 0.6750 train_acc: 58.2% val_loss: 0.6692 val_acc: 59.8%
Epoch 4/10 - train_loss: 0.6579 train_acc: 61.0% val_loss: 0.6401 val_acc: 64.1%
Epoch 5/10 - train_loss: 0.6087 train_acc: 66.8% val_loss: 0.5821 val_acc: 69.4%
Epoch 6/10 - train_loss: 0.5681 train_acc: 70.9% val_loss: 0.5468 val_acc: 72.5%
Epoch 7/10 - train_loss: 0.5352 train_acc: 73.7% val_loss: 0.5227 val_acc: 73.7%
Epoch 8/10 - train_loss: 0.5092 train_acc: 75.6% val_loss: 0.5032 val_acc: 75.1%
Epoch 9/10 - train_loss: 0.4849 train_acc: 77.4% val_loss: 0.4930 val_acc: 76.1%
Epoch 10/10 - train_loss: 0.4614 train_acc: 78.8% val_loss: 0.4756 val_acc: 77.2%
3. PyTorch with Keras initialization for LSTM, FC and embedding layers
Epoch 1/10 - train_loss: 0.6925 train_acc: 52.9% val_loss: 0.6914 val_acc: 54.3%
Epoch 2/10 - train_loss: 0.6532 train_acc: 65.5% val_loss: 0.5858 val_acc: 71.3%
Epoch 3/10 - train_loss: 0.3899 train_acc: 84.1% val_loss: 0.3455 val_acc: 85.5%
Epoch 4/10 - train_loss: 0.2918 train_acc: 88.9% val_loss: 0.3251 val_acc: 87.1%
Epoch 5/10 - train_loss: 0.2560 train_acc: 90.7% val_loss: 0.3118 val_acc: 87.0%
Epoch 6/10 - train_loss: 0.2296 train_acc: 91.6% val_loss: 0.3139 val_acc: 87.2%
Epoch 7/10 - train_loss: 0.2143 train_acc: 92.4% val_loss: 0.3184 val_acc: 87.4%
Epoch 8/10 - train_loss: 0.1994 train_acc: 93.1% val_loss: 0.3214 val_acc: 86.7%
Epoch 9/10 - train_loss: 0.1884 train_acc: 93.6% val_loss: 0.3710 val_acc: 86.6%
Epoch 10/10 - train_loss: 0.1778 train_acc: 94.1% val_loss: 0.3532 val_acc: 86.8%
4. Keras with default initialization
Epoch 1/10
313/313 [==============================] - 36s 64ms/step - loss: 1.0010 - accuracy: 0.5021 - val_loss: 0.9109 - val_accuracy: 0.4950
Epoch 2/10
313/313 [==============================] - 17s 41ms/step - loss: 0.8168 - accuracy: 0.5490 - val_loss: 0.5762 - val_accuracy: 0.7708
Epoch 3/10
313/313 [==============================] - 17s 41ms/step - loss: 0.4688 - accuracy: 0.8442 - val_loss: 0.4313 - val_accuracy: 0.8598
Epoch 4/10
313/313 [==============================] - 17s 41ms/step - loss: 0.3701 - accuracy: 0.8872 - val_loss: 0.3923 - val_accuracy: 0.8556
Epoch 5/10
313/313 [==============================] - 17s 41ms/step - loss: 0.3189 - accuracy: 0.9038 - val_loss: 0.3869 - val_accuracy: 0.8700
Epoch 6/10
313/313 [==============================] - 17s 41ms/step - loss: 0.2852 - accuracy: 0.9148 - val_loss: 0.4007 - val_accuracy: 0.8396
Epoch 7/10
313/313 [==============================] - 17s 41ms/step - loss: 0.2674 - accuracy: 0.9225 - val_loss: 0.3758 - val_accuracy: 0.8668
Epoch 8/10
313/313 [==============================] - 17s 42ms/step - loss: 0.2492 - accuracy: 0.9280 - val_loss: 0.3663 - val_accuracy: 0.8700
Epoch 9/10
313/313 [==============================] - 17s 41ms/step - loss: 0.2353 - accuracy: 0.9334 - val_loss: 0.3772 - val_accuracy: 0.8678
Epoch 10/10
313/313 [==============================] - 17s 41ms/step - loss: 0.2218 - accuracy: 0.9389 - val_loss: 0.3952 - val_accuracy: 0.8732
Here is my code:
1. Set up dataset and dataloader
import pandas as pd
import numpy as np
import re
from bs4 import BeautifulSoup
import multiprocessing as mp
from sklearn.model_selection import train_test_split
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence, pack_padded_sequence
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torchinfo import summary
def cleanup_text(text):
#strip html tags
soup = BeautifulSoup(text, "html.parser")
txt = soup.get_text()
# remove punctuation and use lower case
txt = re.sub(r'[^a-zA-Z0-9 ]', '', txt).lower()
# remove multiple spaces
txt = re.sub(r' +', ' ', txt)
# remove newline
txt = re.sub(r'\n', ' ', txt)
return txt
# load data and preprocess
data = pd.read_csv('drive/MyDrive/colab/imdb/IMDB Dataset.csv')
data['label'] = data['sentiment'].apply(lambda x: 1 if x == 'positive' else 0)
with mp.Pool(mp.cpu_count()) as pool:
data['clean_review'] = pool.map(cleanup_text, data['review'])
# split data into train/validation/test
train_pd, test_pd = train_test_split(data[['clean_review', 'label']], test_size=0.5, random_state=42)
train_pd, val_pd = train_test_split(train_pd, test_size=0.2, random_state=42)
# build vocab
tokenizer = get_tokenizer('basic_english')
def yield_tokens(df_pd):
for i in range(len(df_pd)):
yield tokenizer(train_pd.iloc[i, 0])
vocab = build_vocab_from_iterator(yield_tokens(train_pd), specials=["<unk>", "<pad>"], max_tokens=5000)
vocab.set_default_index(vocab["<unk>"])
# build data
class MyDataset(Dataset):
def __init__(self, df_pd, vocab, tokenizer, max_len=None):
self.df = df_pd
self.stoi = lambda x: vocab(tokenizer(x))
self.itos = lambda x: vocab.lookup_tokens(x)
self.max_len = max_len
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
seq = self.stoi(self.df.iloc[idx, 0])
label = self.df.iloc[idx, 1]
if self.max_len is not None:
trunc = min(len(seq), self.max_len)
seq = seq[:trunc]
return torch.tensor(seq, dtype=torch.int32), torch.tensor(label, dtype=torch.float32)
class MyCollate:
def __init__(self, pad_idx):
self.pad_idx = pad_idx
def __call__(self, batch):
text_list, label_list, len_list = [], [], []
for (_text, _label) in batch:
label_list.append(_label)
text_list.append(_text)
len_list.append(len(_text))
return (pad_sequence(text_list, padding_value=self.pad_idx), torch.tensor(label_list),
torch.tensor(len_list, dtype=torch.int32))
torch.manual_seed(42)
pad_idx = vocab.get_stoi()['<pad>']
train_ds = MyDataset(train_pd, vocab, tokenizer, max_len=450)
train_loader = DataLoader(train_ds, batch_size=64, shuffle=True, drop_last=True,
collate_fn = MyCollate(pad_idx))
val_ds = MyDataset(val_pd, vocab, tokenizer, max_len=450)
val_loader = DataLoader(val_ds, batch_size=64, shuffle=False, drop_last=False,
collate_fn = MyCollate(pad_idx))
test_ds = MyDataset(test_pd, vocab, tokenizer, max_len=450)
test_loader = DataLoader(test_ds, batch_size=64, shuffle=False, drop_last=False,
collate_fn = MyCollate(pad_idx))
2. PyTorch model
# Get cpu or gpu device for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
class LSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim, lstm_unit, lstm_layer, hidden_unit, dropout_prob):
super().__init__()
self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim, padding_idx=1)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=lstm_unit, num_layers=lstm_layer,
bidirectional=True)
self.fc1 = nn.Linear(lstm_unit * 2, hidden_unit)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(dropout_prob)
self.fc2 = nn.Linear(hidden_unit, 1)
self.sigmoid = nn.Sigmoid()
self.lstm_unit = lstm_unit
self.lstm_layer = lstm_layer
# comment out the next two lines if using PyTorch default initialization
nn.init.uniform_(self.embedding.weight, -0.05, 0.05)
self._reinitialize()
def _reinitialize(self):
"""
Tensorflow/Keras-like initialization
"""
for name, p in self.named_parameters():
if 'lstm' in name:
if 'weight_ih' in name:
nn.init.xavier_uniform_(p.data)
elif 'weight_hh' in name:
nn.init.orthogonal_(p.data)
elif 'bias_ih' in name:
p.data.fill_(0)
# Set forget-gate bias to 1
n = p.size(0)
p.data[(n // 4):(n // 2)].fill_(1)
elif 'bias_hh' in name:
p.data.fill_(0)
elif 'fc' in name:
if 'weight' in name:
nn.init.xavier_uniform_(p.data)
elif 'bias' in name:
p.data.fill_(0)
def init_hidden(self, batch_size):
h, c = (torch.zeros(self.lstm_layer * 2, batch_size, self.lstm_unit),
torch.zeros(self.lstm_layer * 2, batch_size, self.lstm_unit))
return h.to(device), c.to(device)
def forward(self, text, text_lengths):
batch_size = text.shape[1]
h_0, c_0 = self.init_hidden(batch_size)
embedded = self.embedding(text)
packed_embedded = pack_padded_sequence(embedded, text_lengths.cpu(), enforce_sorted=False)
output, (h_n, c_n) = self.lstm(packed_embedded, (h_0, c_0))
cat = torch.cat((h_n[-2, :, :], h_n[-1, :, :]), dim=1)
dense = self.fc1(cat)
rel = self.relu(dense)
drop = self.dropout(rel)
preds = self.fc2(drop)
logits = self.sigmoid(preds)
return logits
def train(dataloader, model, loss_fn, optimizer):
training_loss, correct = 0, 0
model.train()
for batch, (text, labels, lengths) in enumerate(dataloader):
text, labels, lengths = text.to(device), labels.to(device), lengths.to(device)
# Compute prediction error
pred = model(text, lengths)
loss = loss_fn(pred, labels.reshape(-1, 1))
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Compute metrics
training_loss += loss.item()
correct += (pred.reshape(-1).round() == labels).type(torch.float).mean().item()
return training_loss / len(dataloader), correct / len(dataloader)
def evaluate(dataloader, model, loss_fn):
size = len(dataloader.dataset)
model.eval()
eval_loss, correct = 0, 0
with torch.no_grad():
for text, labels, lengths in dataloader:
text, labels, lengths = text.to(device), labels.to(device), lengths.to(device)
pred = model(text, lengths)
eval_loss += loss_fn(pred, labels.reshape(-1, 1)).item() * len(labels)
correct += (pred.reshape(-1).round() == labels).type(torch.float).sum().item()
return eval_loss / size, correct / size
3. Train model for 10 epochs
vocab_size = 5000
embedding_dim = 64
lstm_unit = 64
lstm_layer = 1
hidden_unit = 64
dropout_prob = 0.5
model = LSTM(vocab_size, embedding_dim, lstm_unit, lstm_layer, hidden_unit, dropout_prob).to(device)
print(model)
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(),
lr=1e-4,
betas=[0.9,0.999],
eps=1e-7,
weight_decay=1e-3,
amsgrad=False)
run_dict = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
epochs = 10
torch.manual_seed(42)
for t in range(epochs):
train_loss, train_acc = train(train_loader, model, loss_fn, optimizer)
val_loss, val_acc = evaluate(val_loader, model, loss_fn)
print(f"Epoch {t+1:>2d}/{epochs} - train_loss: {train_loss:>0.4f} train_acc: {(100*train_acc):>0.1f}% "
f"val_loss: {val_loss:>0.4f} val_acc: {(100*val_acc):>0.1f}% ")
run_dict['train_loss'].append(train_loss)
run_dict['train_acc'].append(train_acc)
run_dict['val_loss'].append(val_loss)
run_dict['val_acc'].append(val_acc)
4. Similar Keras model
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(num_words=5000, oov_token='<UNK>')
tokenizer.fit_on_texts(train_pd['clean_review'])
train_sequences = tokenizer.texts_to_sequences(train_pd['clean_review'])
val_sequences = tokenizer.texts_to_sequences(val_pd['clean_review'])
test_sequences = tokenizer.texts_to_sequences(test_pd['clean_review'])
def gen_train(stop):
i = 0
while i < stop:
trunc = min(len(train_sequences[i]), 450)
yield train_sequences[i][:trunc], train_pd['label'].iloc[i]
i += 1
def gen_val(stop):
i = 0
while i < stop:
trunc = min(len(val_sequences[i]), 450)
yield val_sequences[i][:trunc], val_pd['label'].iloc[i]
i += 1
def gen_test(stop):
i = 0
while i < stop:
trunc = min(len(test_sequences[i]), 450)
yield test_sequences[i][:trunc], test_pd['label'].iloc[i]
i += 1
train_data = tf.data.Dataset.from_generator(
gen_train,
args=[len(train_sequences)],
output_signature=(tf.TensorSpec(shape=(None,), dtype=tf.int32),
tf.TensorSpec(shape=(), dtype=tf.int32)))
val_data = tf.data.Dataset.from_generator(
gen_val,
args=[len(val_sequences)],
output_signature=(tf.TensorSpec(shape=(None,), dtype=tf.int32),
tf.TensorSpec(shape=(), dtype=tf.int32)))
test_data = tf.data.Dataset.from_generator(
gen_test,
args=[len(test_sequences)],
output_signature=(tf.TensorSpec(shape=(None,), dtype=tf.int32),
tf.TensorSpec(shape=(), dtype=tf.int32)))
train_dataset = (train_data
.shuffle(20000)
.padded_batch(64))
val_dataset = (val_data
.padded_batch(64))
test_dataset = (test_data
.padded_batch(64))
model = tf.keras.Sequential([
tf.keras.layers.Embedding(5000, 64),
tf.keras.layers.Masking(mask_value=0),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64, kernel_regularizer=tf.keras.regularizers.l2(0.001), recurrent_regularizer=tf.keras.regularizers.l2(0.001))),
tf.keras.layers.Dense(64, activation='relu', kernel_regularizer=tf.keras.regularizers.l2(0.001)),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(1)
])
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),
metrics=['accuracy'])
history = model.fit(train_dataset, epochs=10, validation_data=val_dataset)
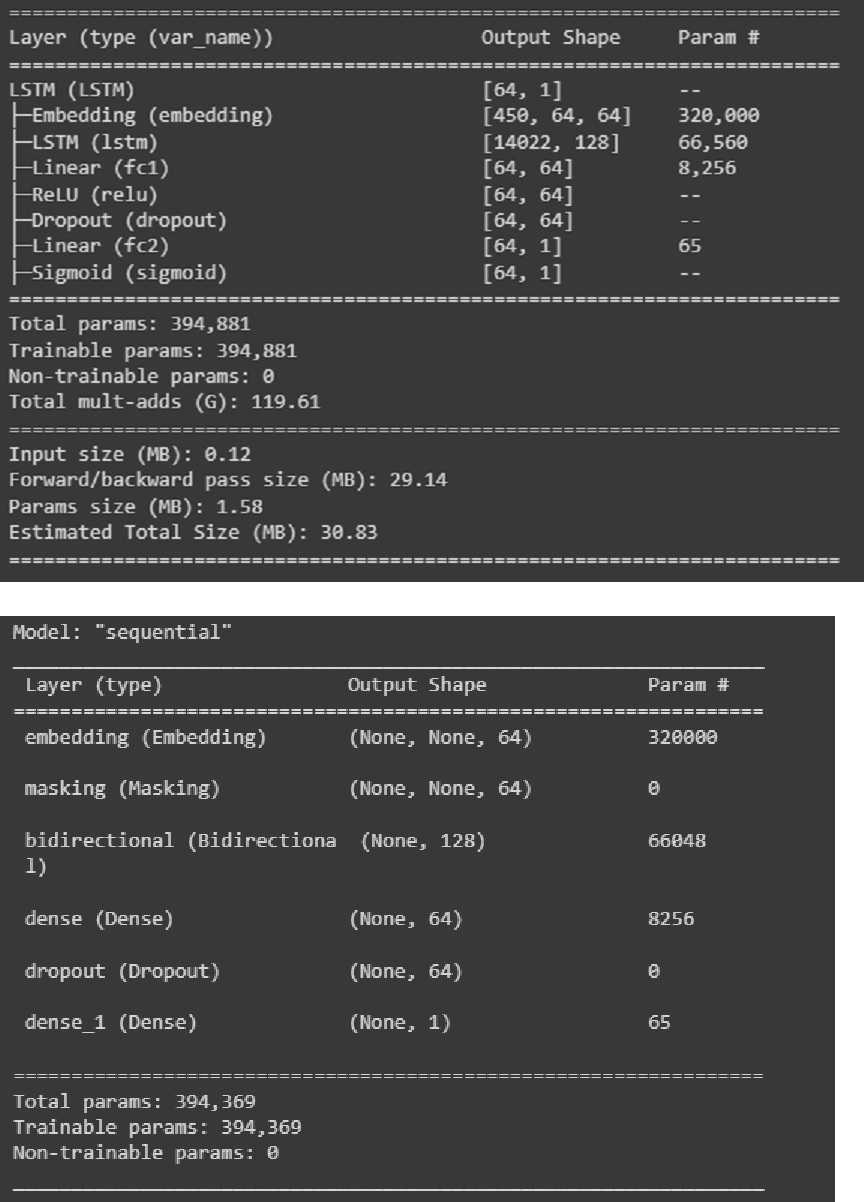
The models are largely similar (I am not sure why there was a small difference in the number of parameters). Here are the model summary for my PyTorch and Keras models: