Generally, I work with Pytorch v1, recently, I decided to make an upgrade to Pytorch v2.
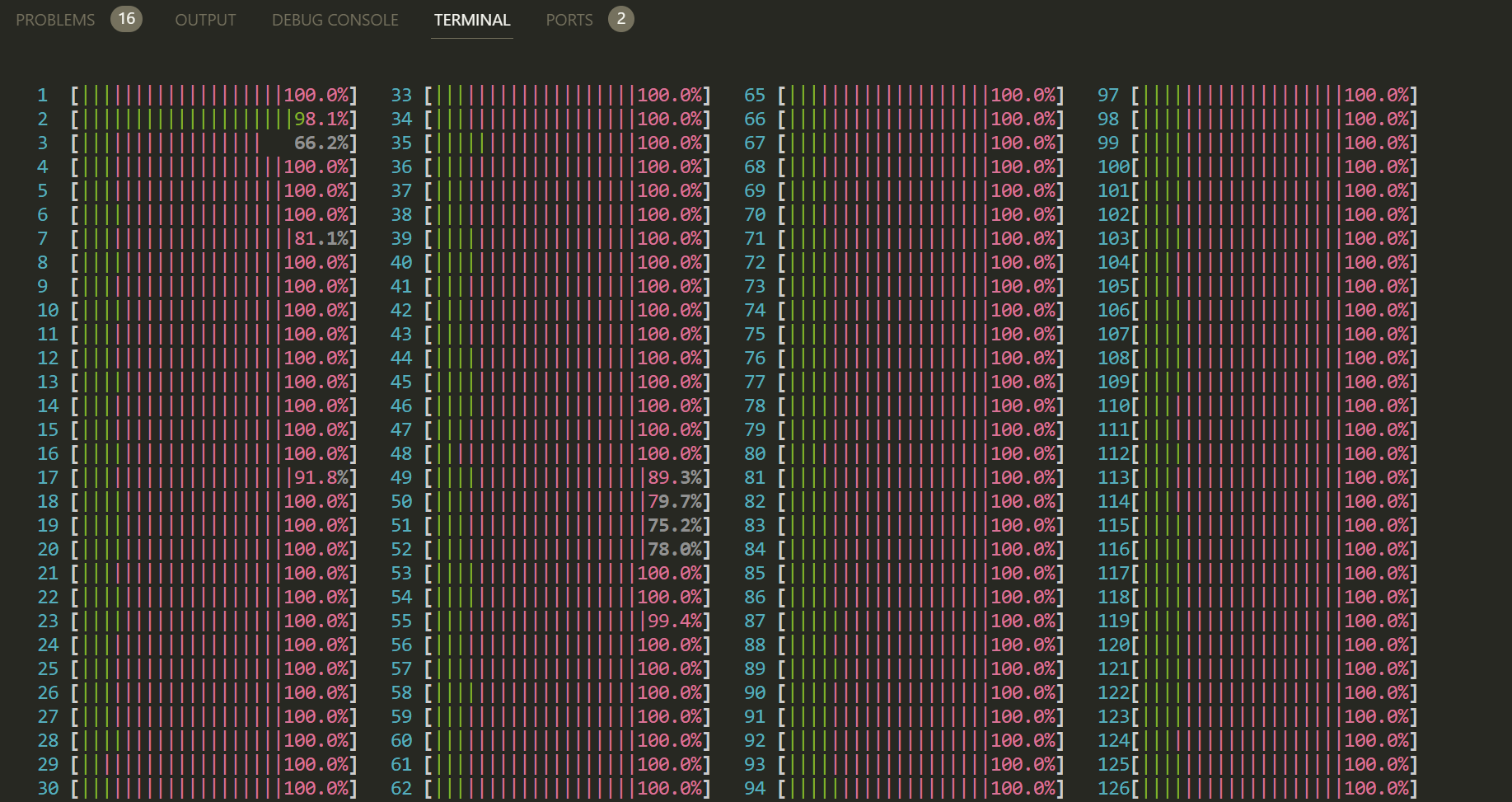
However, I notice that that the cpu consumption is really high. It’s almost more than 70%.
My task is image classification using resnet/mobilnet, and I am working with Flower102 Dataset(dummy data, just for reference)
I have gone through the resources such as the followings:
My System Specs:
Ubuntu 22.04.4 LTS
conda: 23.7.4
Python: 3.12.2
torch: 2.2.1
nvidia driver: 555.42.06(12.4 cuda)
Since pytorch v1 works seemlessly for me, I figured its driver/dependecy issue with pytorchv2, so I tried different variations.
But I have tried the sasme process with:
- Python package manager: pip, conda, built from source
- Python versions: 3.12.2, 3.10.14
- torch versions: 2.2.1, 2.1.2
- nvidia driver: 555.42.06(12.4 cuda, 12.5 cuda), 470.82.01(12.2 cuda, 12.4 cuda)
What I have tried: - batchsize(I have tried as low as batch size of 8 images)
- pin_memory(in dataloader)
- num_workers(in dataloader)
- OMP_NUM_THREADS(I could not locate this in os environment params, upon checking some docs, this doesn’t really seem like it has any relevance here)
import os
from PIL import Image
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import torchmetrics
from net import Net
from tqdm import tqdm
from torchvision.models import resnet50, ResNet50_Weights
from torchvision.models import resnet101, ResNet101_Weights
from torchvision.models import resnet152, ResNet152_Weights
from torchvision.transforms import v2
from torchvision.transforms import ToTensor
import torchvision.datasets
def train(model, criterion, optimizer, train_loader, val_loader, max_epochs=3, target_accuracy=0.99):
_device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
start_epoch = 0
for epoch in range(start_epoch, max_epochs):
# Training
model.train()
with tqdm(train_loader) as pbar:
pbar.set_description(f"[Train] Epoch {epoch}")
for images, labels in pbar:
images = images.to(_device)
labels = labels.to(_device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
loss = loss.cpu()
pbar.set_postfix({"loss": loss.item()})
# Validation
model.eval()
metric_acc = torchmetrics.Accuracy("multiclass", num_classes=200)
with tqdm(val_loader) as pbar:
pbar.set_description(f"[Valid] Epoch {epoch}")
for images, labels in pbar:
images = images.to(_device)
pred = torch.argmax(model(images), axis=1).cpu()
metric_acc(pred, labels)
pbar.set_postfix({"acc": metric_acc.compute().item()})
if __name__ == "__main__":
transforms_ = v2.Compose([
v2.Resize(size=(300, 300)),
ToTensor(),
])
batch_size = 8
dataset = torchvision.datasets.Flowers102(root="./data", split="train", transform=transforms_, download=True)
n_samples = len(dataset)
train_samples = int(n_samples * 0.95)
val_samples = n_samples - train_samples
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_samples, val_samples])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True, pin_memory=False, num_workers=0)
val_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False)
model=resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
_device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=model.to(_device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
train(model, criterion, optimizer, train_loader, val_loader)
Any points/suggestions would be appreciated.