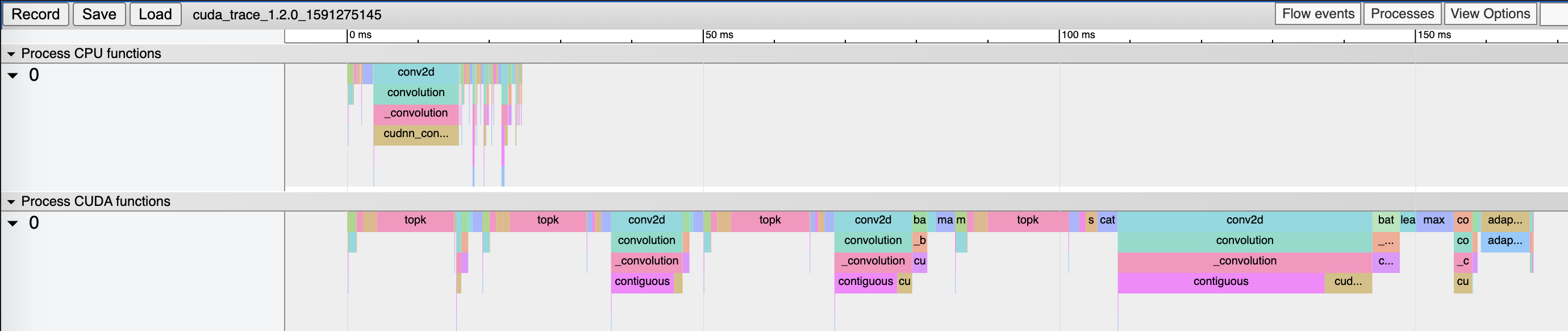
Hi!
I’m working on the official DGCNN (Wang et Al.) PyTorch implementation but I’m encountering strange behaviours among different PyTorch versions (always using Cuda compilation tools V10.1.243).
For some reason the CUDA forward time of a batch seems to be higher (ms --> s) when moving to newer pytorch versions (from 1.4 going on). The tested code is exactly the same, the cuda toolkit also. Any idea why this happens? Thanks!
PyTorch 1.3.1 Forward pass Profiling:
Self CPU time total: 6.875ms
CUDA time total: 264.906ms
PyTorch 1.4 Forward pass Profiling:
Self CPU time total: 27.976ms CUDA time total: 1.498s
PyTorch 1.5 Forward pass Profiling:
Self CPU time total: 12.93ms CUDA time total: 1.434s
(Those are just time measurement for forwarding a batch through the model, the trend is that for newer version of pytorch (>1.4) CUDA time total is in seconds while for older (<1.3.1) is in ms )