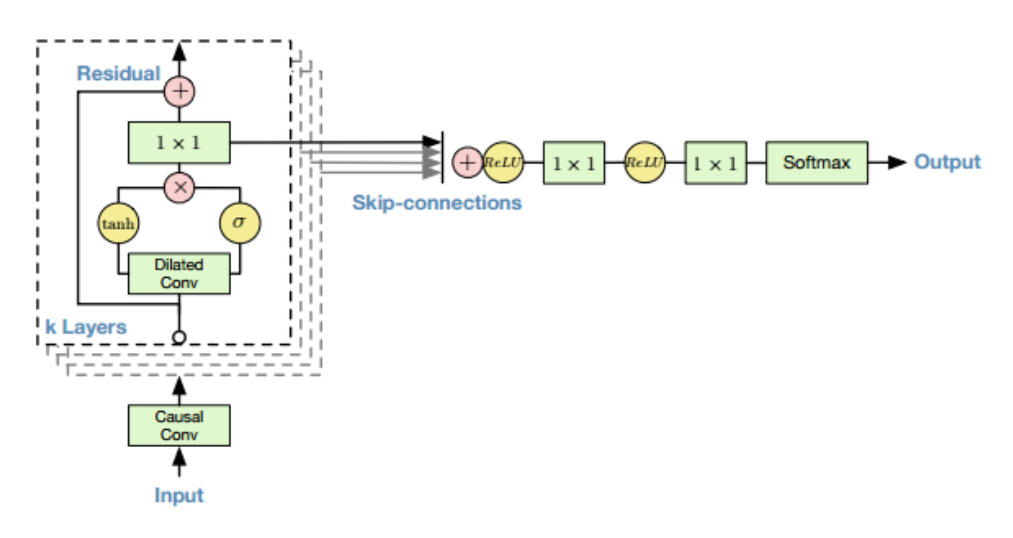
Currently, we are a group doing a project about implementing WaveNet in a Tacotron2 → WaveNet → ASR (Given by firm) for midterm project. We are all novices to PyTorch, but recommended to try this library for constructing our WaveNet. We have a problem with the padding and the F.cross_entropy problem for a given .wav-file.
The main issue is when we compute the loss function. Our output (from WaveNet) is a tensor of shape:
output = tensor([1, 256, 225332]) # [batch_size, sample_size, audio_length]
input = tensor([1, 256, 225360])
There is a problem here, and from what I can see and talk to my supervisor about it is padding the input of the WaveNet. (Cross_entropy wants (N, C) as input and (N) as target, from what I gather, and the dimensions are wrong)
He said “use ‘same’ padding”, but that is currently only operable in TF/Keras as far as I know. We’ve tried to read across multiple posts, but since we’re novices, we can’t seem to figure it out. Any help is appreciated.
This is our WaveNet, which probably has some issues (particularly padding and perhaps causal convolution seems iffy?).
"""
Wavenet model
"""
from torch import nn
import torch
#TODO: Add local and global conditioning
def initialize(m):
"""
Initialize CNN with Xavier_uniform weight and 0 bias.
"""
if isinstance(m, torch.nn.Conv1d):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0.0)
class CausalConv1d(torch.nn.Module):
"""
Causal Convolution for WaveNet
- Jakob
"""
def __init__(self, in_channels, out_channels, kernel_size, dilation = 1, bias = True):
super(CausalConv1d, self).__init__()
# padding=1 for same size(length) between input and output for causal convolution
self.dilation = dilation
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.padding = padding = (kernel_size-1) * dilation # kernelsize = 2, -1 * dilation = 1, = 1. - Jakob.
self.conv = torch.nn.Conv1d(in_channels, out_channels,
kernel_size, padding=padding, dilation=dilation,
bias=bias) # Fixed for WaveNet but not sure
def forward(self, x):
output = self.conv(x)
if self.padding != 0:
output = output[:, :, :-self.padding]
return output
class Wavenet(nn.Module):
def __init__(self,
layers=3,
blocks=2,
dilation_channels=32,
residual_block_channels=512,
skip_connection_channels=512,
output_channels=256,
output_size=32,
kernel_size=3
):
super(Wavenet, self).__init__()
self.layers = layers
self.blocks = blocks
self.dilation_channels = dilation_channels
self.residual_block_channels = residual_block_channels
self.skip_connection_channels = skip_connection_channels
self.output_channels = output_channels
self.kernel_size = kernel_size
self.output_size = output_size
# initialize dilation variables
receptive_field = 1
init_dilation = 1
# List of layers and connections
self.dilations = []
self.residual_convs = nn.ModuleList()
self.filter_conv_layers = nn.ModuleList()
self.gate_conv_layers = nn.ModuleList()
self.skip_convs = nn.ModuleList()
# First convolutional layer
self.first_conv = CausalConv1d(in_channels=self.output_channels,
out_channels=residual_block_channels,
kernel_size = 2)
# Building the Modulelists for the residual blocks
for b in range(blocks):
additional_scope = kernel_size - 1
new_dilation = 1
for i in range(layers):
# dilations of this layer
self.dilations.append((new_dilation, init_dilation))
# dilated convolutions
self.filter_conv_layers.append(nn.Conv1d(in_channels=residual_block_channels, out_channels=dilation_channels, kernel_size=kernel_size, dilation=new_dilation))
self.gate_conv_layers.append(nn.Conv1d(in_channels=residual_block_channels, out_channels=dilation_channels, kernel_size=kernel_size, dilation=new_dilation))
# 1x1 convolution for residual connection
self.residual_convs.append(nn.Conv1d(in_channels=dilation_channels, out_channels=residual_block_channels, kernel_size=1))
# 1x1 convolution for skip connection
self.skip_convs.append(nn.Conv1d(in_channels=dilation_channels,
out_channels=skip_connection_channels,
kernel_size=1))
# Update receptive field and dilation
receptive_field += additional_scope
additional_scope *= 2
init_dilation = new_dilation
new_dilation *= 2
# Last two convolutional layers
self.last_conv_1 = nn.Conv1d(in_channels=skip_connection_channels,
out_channels=skip_connection_channels,
kernel_size=1)
self.last_conv_2 = nn.Conv1d(in_channels=skip_connection_channels,
out_channels=output_channels,
kernel_size=1)
#Calculate model receptive field and the required input size for the given output size
self.receptive_field = receptive_field
self.input_size = receptive_field + output_size - 1
def forward(self, input):
# Feed first convolutional layer with input
x = self.first_conv(input)
# Initialize skip connection
skip = 0
# Residual block
for i in range(self.blocks * self.layers):
(dilation, init_dilation) = self.dilations[i]
# Residual connection bypassing dilated convolution block
residual = x
# input to dilated convolution block
filter = self.filter_conv_layers[i](x)
filter = torch.tanh(filter)
gate = self.gate_conv_layers[i](x)
gate = torch.sigmoid(gate)
x = filter * gate
# Feed into 1x1 convolution for skip connection
s = self.skip_convs[i](x)
#Adding skip & Match size with decreasing dimensionality of x
if skip is not 0:
skip = skip[:, :, -s.size(2):]
skip = s + skip # Sum all skip connections
# Feed into 1x1 convolution for residual connection
x = self.residual_convs[i](x)
#Adding Residual & Match size with decreasing dimensionality of x
x = x + residual[:, :, dilation * (self.kernel_size - 1):]
# print(x.shape)
x = torch.relu(skip)
#Last conv layers
x = torch.relu(self.last_conv_1(x))
x = self.last_conv_2(x)
soft = torch.nn.Softmax(dim=1)
x = soft(x)
return x
The training file:
model = Wavenet(layers=3,blocks=2,output_size=32).to(device)
model.apply(initialize) # xavier_uniform_ : Does this work?
model.train()
optimizer = optim.Adam(model.parameters(), lr=0.0003)
for i, batch in tqdm(enumerate(train_loader)):
mu_enc_my_x = encode_mu_law(x=batch, mu=256)
input_tensor = one_hot_encoding(mu_enc_my_x)
input_tensor = input_tensor.to(device)
output = model(input_tensor)
# TODO: Inspect input/output formats, maybe something wrong....
loss = F.cross_entropy(output.T.reshape(-1, 256), input_tensor[:,:,model.input_size - model.output_size:].long().to(device)) # subtract receptive field instead of pad it, workaround for quick debugging of loss-issue.
print("\nLoss:", loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 1000 == 0:
print("\nSaving model")
torch.save(model.state_dict(), "wavenet.pt")