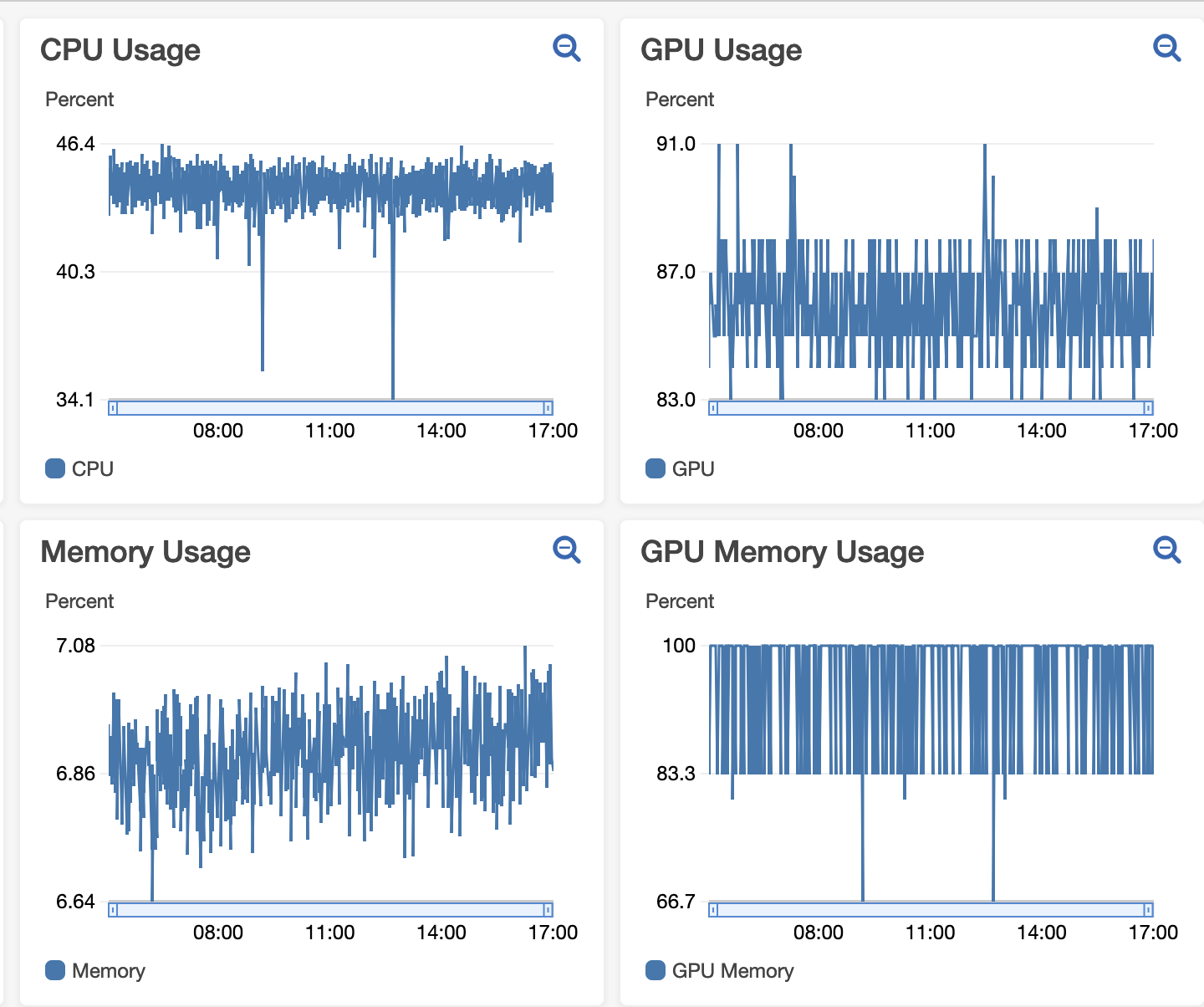
Say, we have 30K records and the dataloader is feeding in batches of size 32 to a V100. The dataloader has 8 num_workers.
The setup is as follows:
#model init
#dataset init
for (id_batch, img_batch) in data_loader:
probs = mysterious_function(img_batch)
The forward pass happens inside the mysterious_function :
def mysterious_function(image_batch):
image_batch_gpu_var = Variable(torch.squeeze(image_batch), requires_grad=False).type(self.dtype_float).cuda(device=self.gpu_id)
prob_predict_gpu = self.seg_net(image_batch_gpu_var)['probs']
prob_predict_res = prob_predict_gpu.data.cpu().numpy()
return prob_predict_res
The time tracker computes the execution time of the decorated function and logs the result right to stdout after it finishes execution. Here is the output of the time tracker:
mysterious_function running time on batch 0 0.141 seconds
mysterious_function running time on batch 1 2.420 seconds
mysterious_function running time on batch 2 0.106 seconds
mysterious_function running time on batch 3 2.391 seconds
mysterious_function running time on batch 4 0.113 seconds
mysterious_function running time on batch 5 2.341 seconds
mysterious_function running time on batch 6 0.117 seconds
mysterious_function running time on batch 7 2.393 seconds
mysterious_function running time on batch 8 0.122 seconds
mysterious_function running time on batch 9 2.257 seconds
Curious to know if this had anything to do with the dataloader read/decode/resizing from NFS, I ran the same forward pass twice on the same batch of data.
def mysterious_function(image_batch):
cp1 = time()
image_batch_gpu_var = Variable(torch.squeeze(image_batch), requires_grad=False).type(self.dtype_float).cuda(device=self.gpu_id)
cp2 = time()
print('moving image batch of shape {} to GPU {}'.format(image_batch_var.shape, cp2 - cp1)
prob_predict_gpu = self.seg_net(image_batch_gpu_var)['probs']
cp3 = time()
print('model forward pass 1 out of 2 {}'.format(image_batch_var.shape, cp3 - cp2))
prob_predict_gpu = self.seg_net(image_batch_gpu_var)['probs']
cp4 = time()
print('model forward pass 2 out of 2 {}'.format(image_batch_var.shape, cp4 - cp3))
#note time taken
prob_predict_res = prob_predict_gpu.data.cpu().numpy()
return prob_predict_res
[] mysterious function running time 1.303
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.0034639835357666016 seconds
model forward pass 1 of 2 takes 0.12161993980407715 seconds
model forward pass 2 of 2 takes 1.1894159317016602 seconds
[] mysterious function running time 1.317
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.003448963165283203 seconds
model forward pass 1 of 2 takes 0.1061561107635498 seconds
model forward pass 2 of 2 takes 1.1635644435882568 seconds
mysterious function running time 1.275
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.0034742355346679688 seconds
model forward pass 1 of 2 takes 0.10687828063964844 seconds
model forward pass 2 of 2 takes 0.8193213939666748 seconds
[] mysterious function running time 0.932
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.0034782886505126953 seconds
model forward pass 1 of 2 takes 0.09704208374023438 seconds
model forward pass 2 of 2 takes 1.1900320053100586 seconds
[] mysterious function running time 1.293
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.003448486328125 seconds
segnet forward pass 1 of 2 takes 0.13462281227111816 seconds
segnet forward pass 2 of 2 takes 1.1501150131225586 seconds
[] mysterious function running time 1.291
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.00835871696472168 seconds
segnet forward pass 1 of 2 takes 0.09815263748168945 seconds
segnet forward pass 2 of 2 takes 1.0340092182159424 seconds
[] mysterious function running time 1.143
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.0038101673126220703 seconds
segnet forward pass 1 of 2 takes 0.1068427562713623 seconds
segnet forward pass 2 of 2 takes 1.1246507167816162 seconds
[] mysterious function running time 1.238
moving image batch of shape torch.Size([32, 3, 224, 224]) to GPU 0.003797292709350586 seconds
segnet forward pass 1 of 2 takes 0.10389494895935059 seconds
segnet forward pass 2 of 2 takes 1.2108190059661865 seconds
As you can see, the 2nd forward pass takes almost 10x more time than the first forward pass on the same batch.
So, back to one forward pass and I tried to free up cuda memory after the first forward pass, but it did not help:
@time_tracker(_log)
def mysterious_function(image_batch):
image_batch_gpu_var = Variable(torch.squeeze(image_batch), requires_grad=False).type(self.dtype_float).cuda(device=self.gpu_id)
prob_predict_gpu = self.seg_net(image_batch_gpu_var)['probs']
torch.cuda.empty_cache()
prob_predict_res = prob_predict_gpu.data.cpu().numpy()
return prob_predict_res
mysterious function running time on batch 0 0.729 seconds
mysterious function running time on batch 1 2.190seconds
mysterious function running time on batch 2 0.171seconds
mysterious function running time on batch 3 1.912seconds
mysterious function running time on batch 4 0.152seconds
mysterious function running time on batch 5 2.329seconds
Something seems to be wrong with the odd batch.