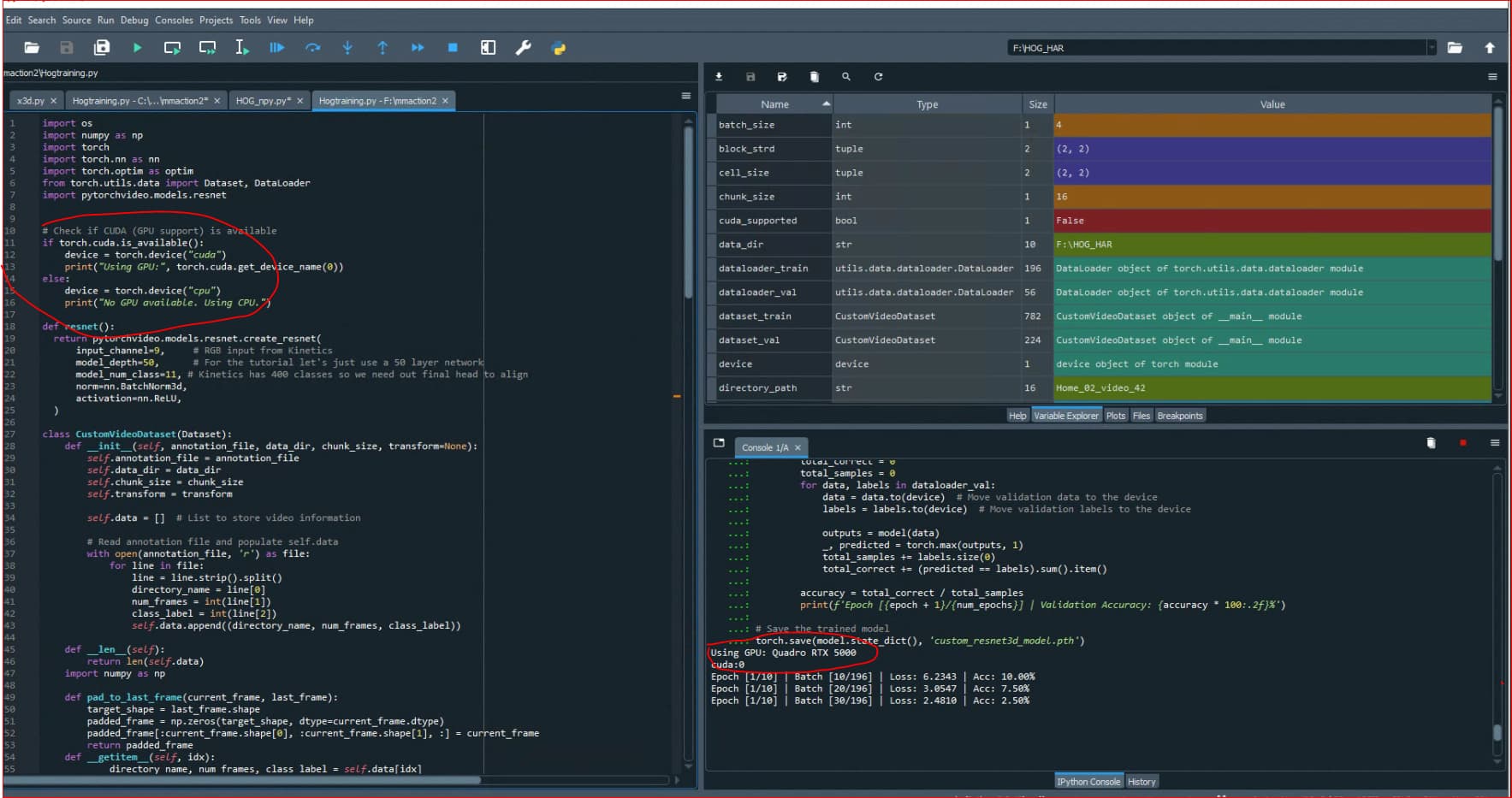
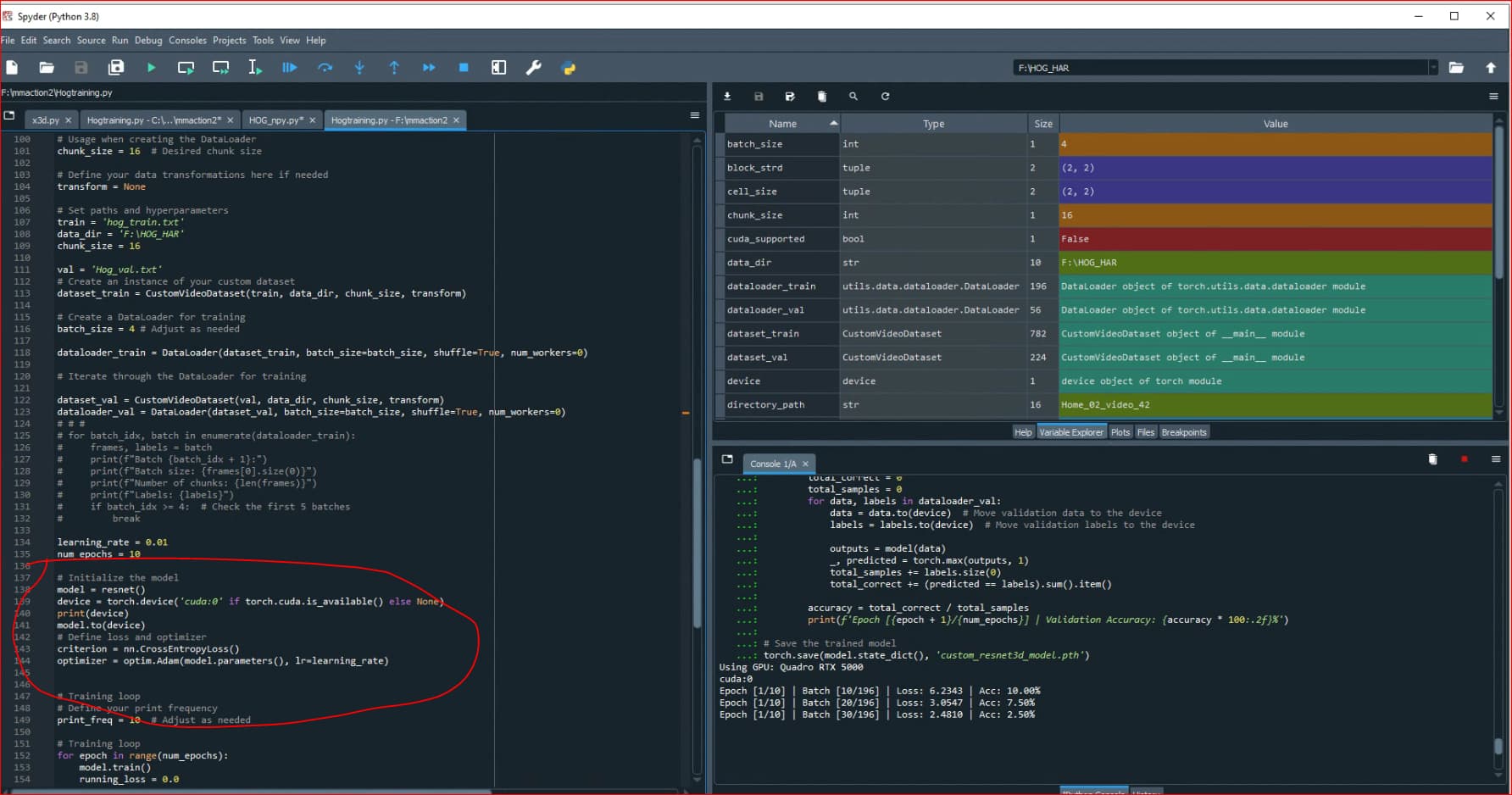
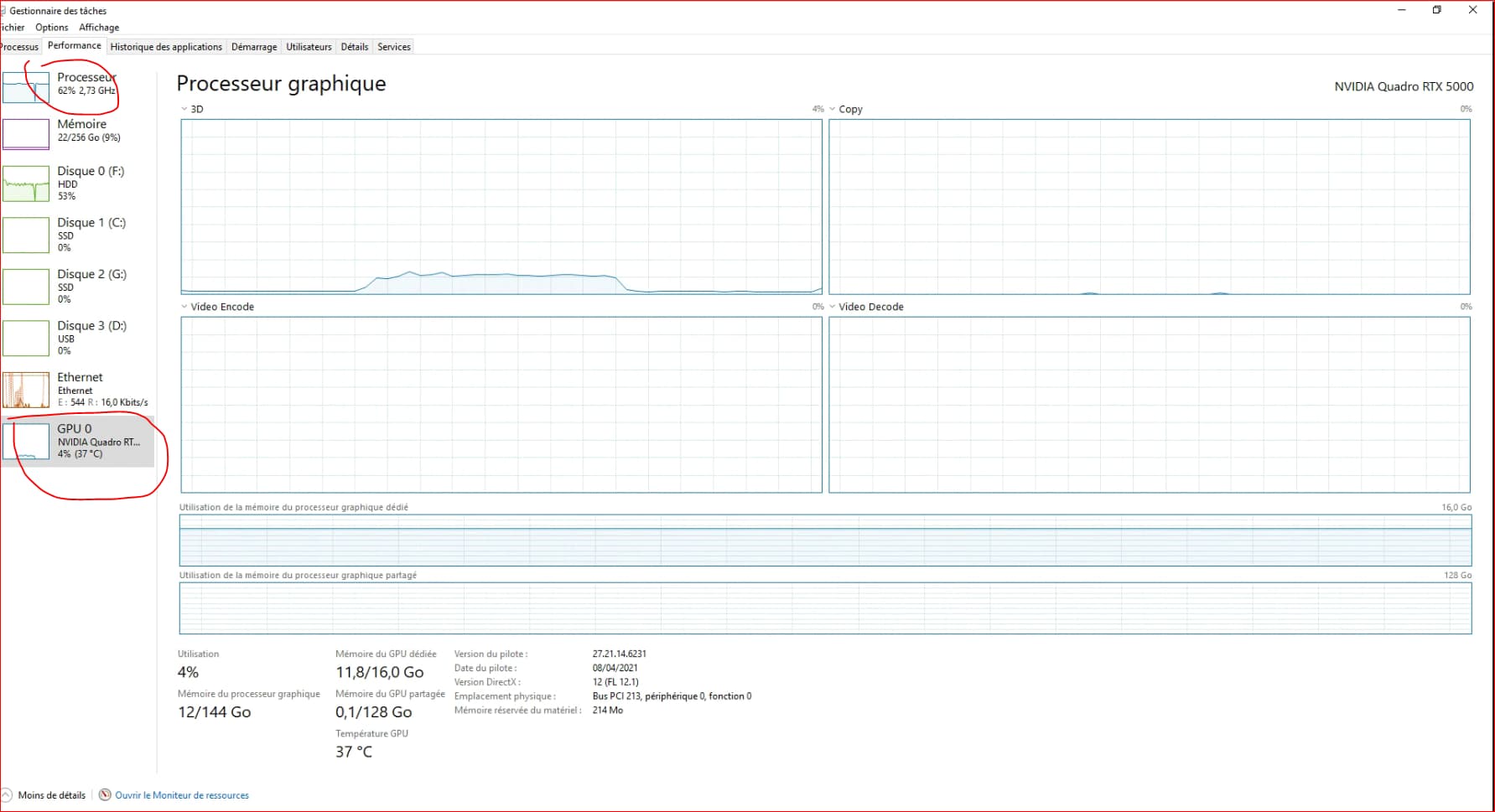
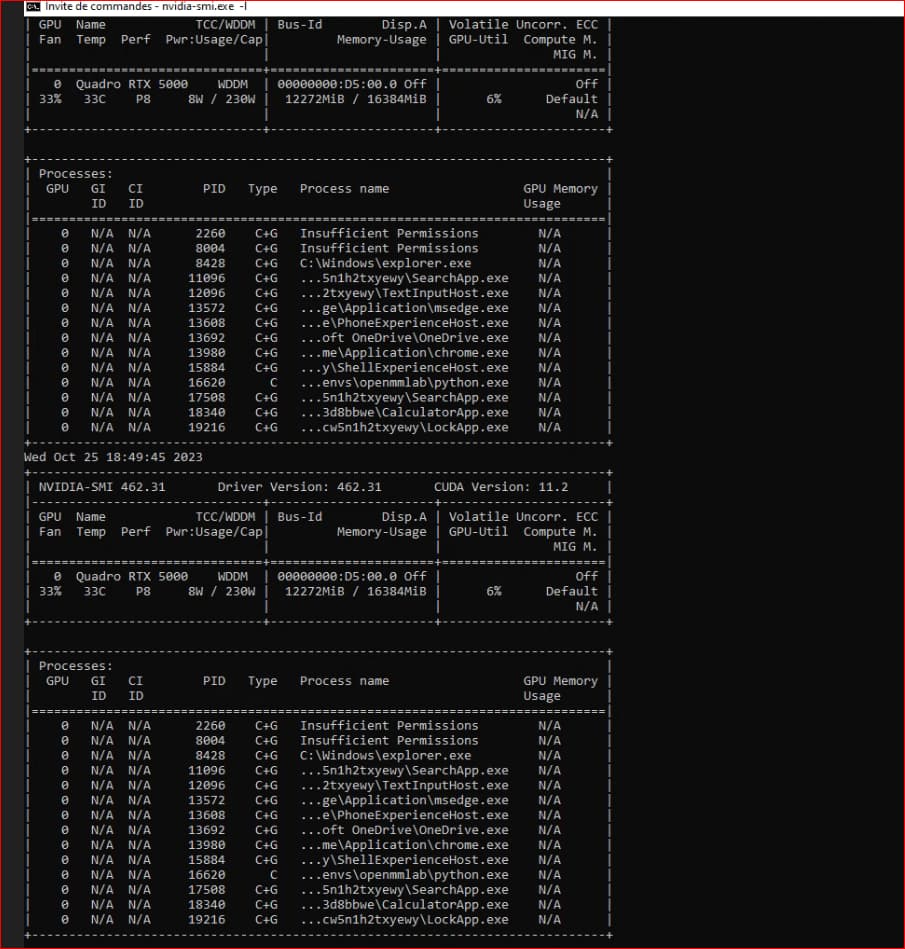
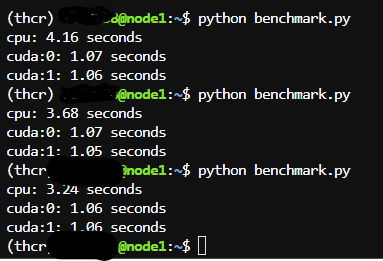
cuda installed , when i check if gpu is detected, it is true. I setup training in pytorch, mmaction2 , the training is still on the CPU.
Using GPU: Quadro RTX 5000
10/25 12:24:25 - mmengine - INFO -
System environment:
sys.platform: win32
Python: 3.8.18 (default, Sep 11 2023, 13:39:12) [MSC v.1916 64 bit (AMD64)]
CUDA available: True
numpy_random_seed: 1335494315
GPU 0: Quadro RTX 5000
CUDA_HOME: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3
NVCC: Cuda compilation tools, release 11.3, V11.3.109
MSVC: n/a, reason: fileno
PyTorch: 1.10.0+cu102
PyTorch compiling details: PyTorch built with:
-
C++ Version: 199711
-
MSVC 192829337
-
Intel(R) Math Kernel Library Version 2020.0.2 Product Build 20200624 for Intel(R) 64 architecture applications
-
Intel(R) MKL-DNN v2.2.3 (Git Hash 7336ca9f055cf1bfa13efb658fe15dc9b41f0740)
-
OpenMP 2019
-
LAPACK is enabled (usually provided by MKL)
-
CPU capability usage: AVX512
-
CUDA Runtime 10.2
-
NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_61,code=sm_61;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_37,code=compute_37
-
CuDNN 7.6.5
-
Magma 2.5.4
-
Build settings: BLAS_INFO=mkl, BUILD_TYPE=Release, CUDA_VERSION=10.2, CUDNN_VERSION=7.6.5, CXX_COMPILER=C:/w/b/windows/tmp_bin/sccache-cl.exe, CXX_FLAGS=/DWIN32 /D_WINDOWS /GR /EHsc /w /bigobj -DUSE_PTHREADPOOL -openmp:experimental -IC:/w/b/windows/mkl/include -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DUSE_FBGEMM -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO, LAPACK_INFO=mkl, PERF_WITH_AVX=1, PERF_WITH_AVX2=1, PERF_WITH_AVX512=1, TORCH_VERSION=1.10.0, USE_CUDA=ON, USE_CUDNN=ON, USE_EXCEPTION_PTR=1, USE_GFLAGS=OFF, USE_GLOG=OFF, USE_MKL=ON, USE_MKLDNN=ON, USE_MPI=OFF, USE_NCCL=OFF, USE_NNPACK=OFF, USE_OPENMP=ON,
TorchVision: 0.11.1+cu102
OpenCV: 4.5.1
MMEngine: 0.9.0
Runtime environment:
dist_cfg: {‘backend’: ‘nccl’}
seed: 1335494315
Distributed launcher: none
Distributed training: False
GPU number: 1
10/25 12:24:26 - mmengine - INFO - Distributed training is not used, all SyncBatchNorm (SyncBN) layers in the model will be automatically reverted to BatchNormXd layers if they are used.
10/25 12:24:26 - mmengine - INFO - Hooks will be executed in the following order:
before_run:
(VERY_HIGH ) RuntimeInfoHook
(BELOW_NORMAL) LoggerHook
before_train:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(VERY_LOW ) CheckpointHook
before_train_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(NORMAL ) DistSamplerSeedHook
before_train_iter:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
after_train_iter:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
after_train_epoch:
(NORMAL ) IterTimerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
before_val:
(VERY_HIGH ) RuntimeInfoHook
before_val_epoch:
(NORMAL ) IterTimerHook
before_val_iter:
(NORMAL ) IterTimerHook
after_val_iter:
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
after_val_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
(LOW ) ParamSchedulerHook
(VERY_LOW ) CheckpointHook
after_val:
(VERY_HIGH ) RuntimeInfoHook
after_train:
(VERY_HIGH ) RuntimeInfoHook
(VERY_LOW ) CheckpointHook
before_test:
(VERY_HIGH ) RuntimeInfoHook
before_test_epoch:
(NORMAL ) IterTimerHook
before_test_iter:
(NORMAL ) IterTimerHook
after_test_iter:
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
after_test_epoch:
(VERY_HIGH ) RuntimeInfoHook
(NORMAL ) IterTimerHook
(BELOW_NORMAL) LoggerHook
after_test:
(VERY_HIGH ) RuntimeInfoHook
after_run:
(BELOW_NORMAL) LoggerHook
10/25 12:24:26 - mmengine - WARNING - Dataset CustomVideoDataset has no metainfo. dataset_meta in visualizer will be None.
10/25 12:24:26 - mmengine - WARNING - The prefix is not set in metric class Accuracy.
10/25 12:24:26 - mmengine - WARNING - Dataset CustomVideoDataset has no metainfo. dataset_meta in the evaluator, metric and visualizer will be None.
10/25 12:24:26 - mmengine - WARNING - “FileClient” will be deprecated in future. Please use io functions in mmengine.fileio — mmengine 0.11.0rc0 documentation
10/25 12:24:26 - mmengine - INFO - Checkpoints will be saved to F:\HOG_HAR\work_dir.