but i noticed that weight.pt is a quantized tensor, weight.pt has its own scale(what is not equal to
0.027574609965085983) and zero_point,
SO WHO can tell me what are the bias.pt (or as you see, in features.0.0: zero_point=0) and scale.pt (or as you see, in features.0.0: scale=0.027574609965085983) meaning?
(1). bias is the bias argument of the quantized conv relu module, scale is the output_scale for the quantized conv relu module
(2). yes, bias is not quantized.
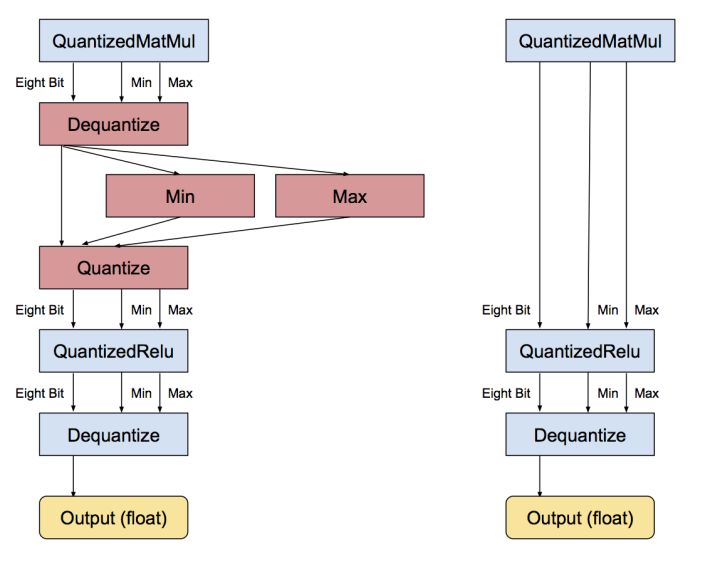
Thank you for your answer. So PyTorch QAT didn’t do full integer inference, is that right? PyTorch just use int input and int weight to do matmul in a layer, there is a dequantize and quantize pair between 2 layers? Do PyTorch support quantize a model to do full integer quantize, which only quantize inputs at first and dequantize output at last?
Thank you for your reply. I find that PyTorchJIT do requantize operation between 2 layers, is that right? And i also find that quantized input(int8) multiply quantized weight(int8) will get a result out of the range of int8, so requantize is necessary. If i need my result quantized in the type of int8, i need to quantize my input and weight in the type of int4, do pytorch support it?
requantization happens in the quantized operator itself, for example quantized::conv2d will requantize the intermediate result (in int32) to int8 with the quantization parameters output_scale/output_zero_point.
int4 support is still in development, @supriyar has more context on that.
int4 support is still in development, @supriyar has more context on that.
We support torch.quint4x2 dtype, which packs two 4bit values into a byte. In order to use this dtype in operators we need kernels that understand this underlying type and can optimally operate on it. But if you wish to use this dtype to save storage space, then it should be supported.
You can find the dtype in the nightly versions.