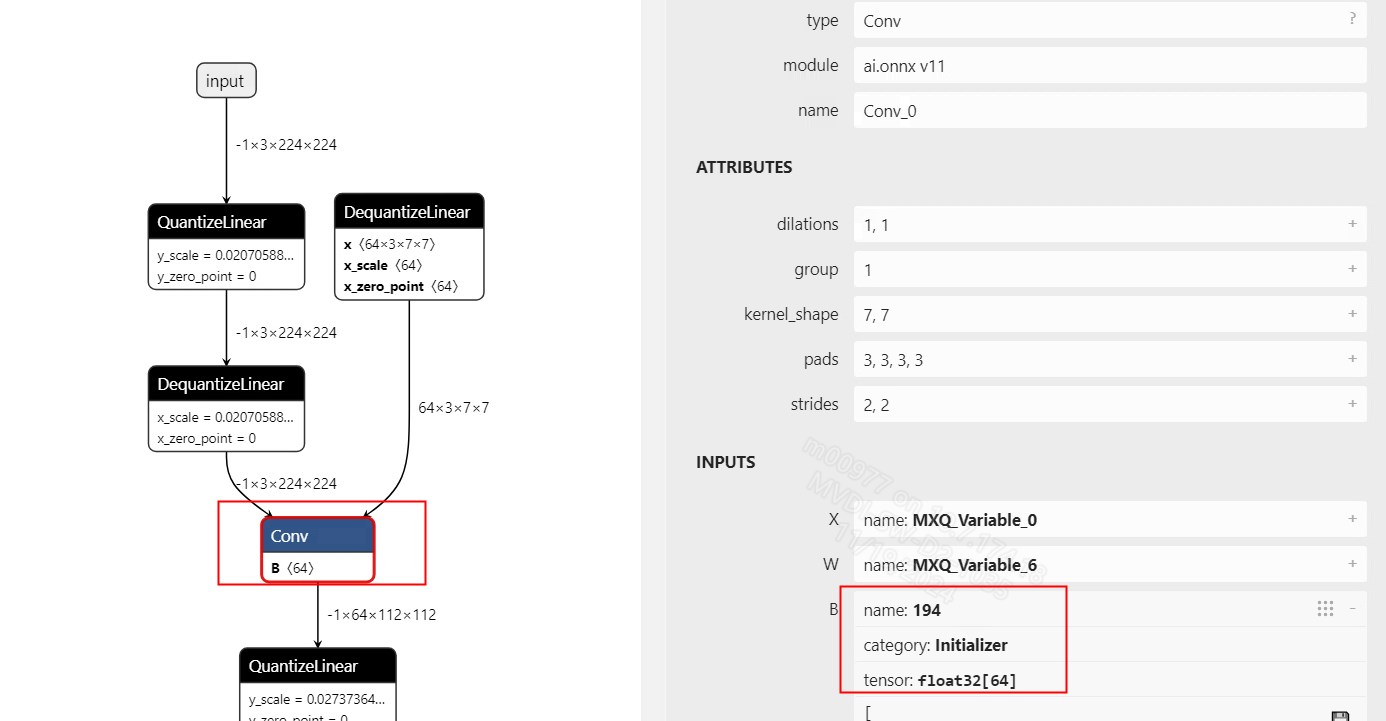
when QuantizedConv2d converted to onnx format,because bias precisoin is float32,so is there a way not converter the bias to dequantized node?
I use qat.
code is:
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_mapping=qconfig_mapping, example_inputs=dummy_input, backend_config=backend_config_s)
model_quantized = quantize_fx.convert_fx(model_prepared)
dummy_input = dummy_input.to(device)
model_quantized.eval()
torch.onnx.export(model_quantized, dummy_input, “saved_models/quantized_model.onnx”,
verbose = False,
input_names = [‘input’],
output_names = [‘output’],
keep_initializers_as_inputs=True
)
thank very much!!!
now is:
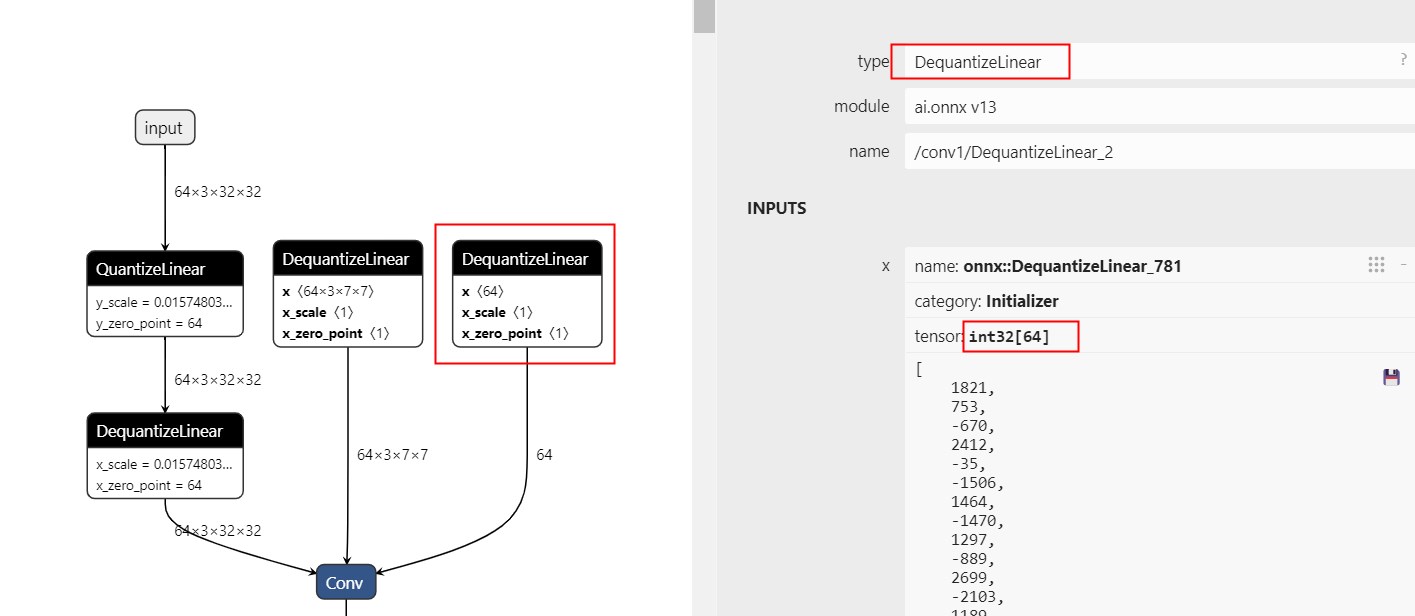
target is: