Hi @weiwei_lee – resnet50 here represents the directory containing Caffe2 or ONNX protobufs. We have a script to download some from utils/download_caffe2_models.sh and utils/download_onnx_models.sh.
@weiwei_lee I’m not exactly sure what the question is – do you have your own model defined in PyTorch that you want to run with Glow, and then use quantization for it?
@weiwei_lee You can do this e.g. by exporting from PyTorch into ONNX, and then load the ONNX proto representation of the model into Glow – see this tutorial. This of course is dependent on what we support in our ONNX importer and in Glow, so not everything you export will work right out of the box.
@weiwei_lee By save, do you mean you want to save the compiled quantized model as a standalone executable for a CPU? We have directions on that here. If not, please clarify what you’re looking for.
Yes, that is what I want.
Is there any document explain more detail about quantization flow and rule in inference stage?
Because I am curious that in glow,
it load model and yaml to transform weight of model into int8?
Input to each layer is float or int8?
is the multiplication rule like tflite using gemmlowp to do int8*int8?
Yes, please take a look at all of our docs – I think they mostly seem that they will answer your questions. Here is the doc on quantization. You gather a profile on the floating point graph with whatever inputs you want, it dumps the yaml file, then you load it back in and it will quantize the graph given the profile you gathered. Assuming the CPU backend supports the node in quantized form, all inputs will be int8. Otherwise conversions to/from int8 will be performed. You can look at the graph that is generated to see what is and is not quantized, via the command line option -dump-graph-DAG="graph.dot".
I am trying to quantize another pytorch model with the approach described in this post. I have glow build and model converted to .onnx , what should I put as the -model-input-name? when i do
./bin/image-classifier tests/images/imagenet/*.png -image-mode=0to1 -m=‘path/to/my/model’ -model-input-name=gpu_0/data -dump-profile=“profile.yaml”
I got error file: ~/glow/lib/Importer/ProtobufLoader.cpp line: 33 message: There is no tensor registered with name 0.
I assume it’s the input name was incorrect?
Yes, it’s probably due to -model-input-name. You’ll need to take a look at the proto itself to find out the name of the external input that is the image itself, which is the input to the first operator of the model. In most of our image classification models, this is data or gpu_0/data. You can see some examples in our image classifier run script here.
@jfix Thank you for the quick respond! How do I get the input name of the model? I have tried print(model) and for name, param in model.named_parameters(): print (name, param.data.shape) , both start from the actual layers, not including the input. sorry it’s a basic question.
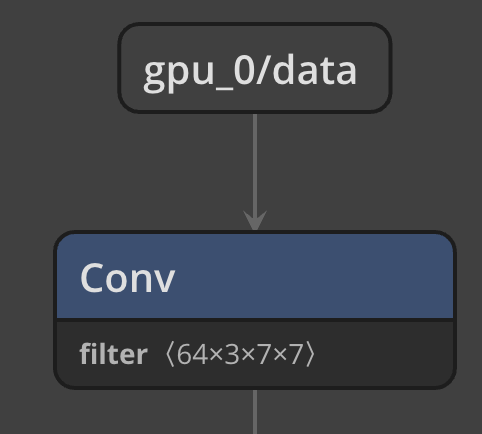
You could use something like Netron to view your protobuf, and view what the very first operator’s input is (see the image below, for the very start of a Caffe2 Resnet50 model – you’d use gpu_0/data). Otherwise you should be able to just inspect the protobuf text of the model to see what the input name of the first operator is – it should be external input.
Thank you for your help @jfix! That works wonders!
However got an error eventually glow/lib/Importer/ONNXModelLoader.cpp line: 896 error code: MODEL_LOADER_UNSUPPORTED_OPERATOR message: Failed to load operator. I guess it means some of the operations in my model are supported for quantization at this point?
Yeah, some op is unsupported – what options were you using for the image-classifier? Was this when trying to get the profile (-dump-profile), or load the profile for quantization (-load-profile)? Have you tried just running it in fp32 (i.e. without the mentioned options)?
For MODEL_LOADER_UNSUPPORTED_OPERATOR, the operator is unsupported in fp32 too, and we’d need to add support to the importer for it. We need to improve our error messages here – in the meantime could you just add a simple print statement just before the RETURN_ERR() in ONNXModelLoader::LoadOperator() to print the typeName to see what it is reporting as unsupported.
Also, feel free to open an issue for supporting whatever op it is on Github!
Thanks @jfix for clarifying it! I got the error when doing ./bin/image-classifier tests/images/imagenet/*.png -image-mode=0to1 -m=‘path/to/my/model’ -model-input-name=gpu_0/data -dump-profile=“profile.yaml” .
The model I am trying to quantize with is mobilefacenet, made with grouped convolutions and dense blocks.