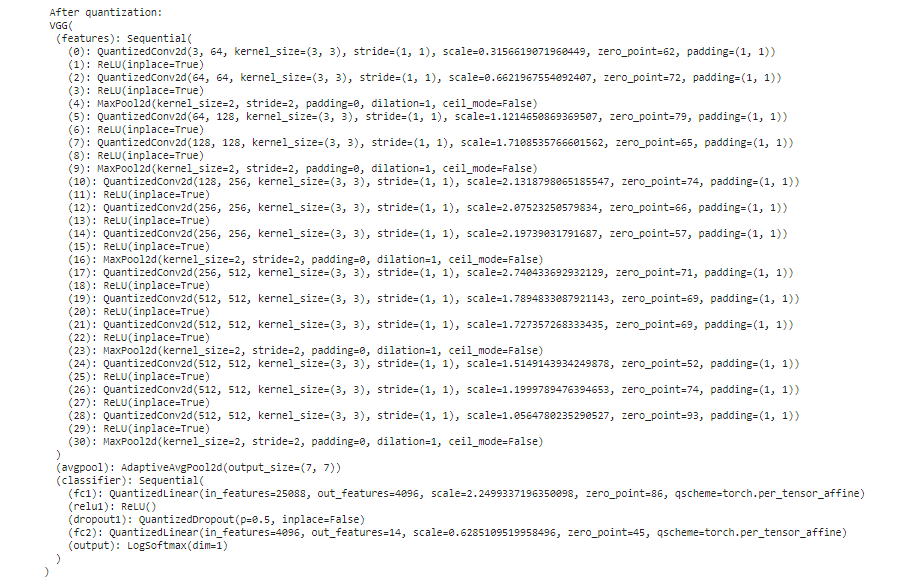
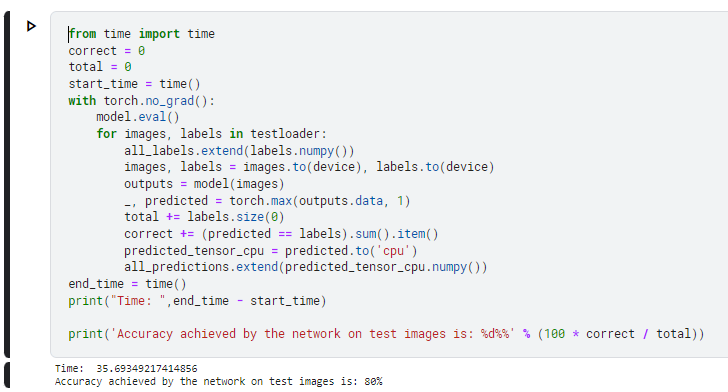
Thank you for the reply.
I am able to run the model without quantization.
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(fc1): Linear(in_features=25088, out_features=4096, bias=True)
(relu1): ReLU()
(dropout1): Dropout(p=0.5, inplace=False)
(fc2): Linear(in_features=4096, out_features=14, bias=True)
(output): LogSoftmax(dim=1)
)
)
This is the model I am using(without quantization).
I am using the model for flower classification and i just want the time take and accuracy of the model.
This is the output i get without quantization.
Collecting environment information…
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.12 | packaged by conda-forge | (main, Jun 23 2023, 22:40:32) [GCC 12.3.0] (64-bit runtime)
Python platform: Linux-5.15.133±x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla T4
GPU 1: Tesla T4
Nvidia driver version: 470.161.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 4
On-line CPU(s) list: 0-3
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) CPU @ 2.00GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
Stepping: 3
BogoMIPS: 4000.24
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat md_clear arch_capabilities
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 64 KiB (2 instances)
L1i cache: 64 KiB (2 instances)
L2 cache: 2 MiB (2 instances)
L3 cache: 38.5 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-3
Vulnerability Gather data sampling: Unknown: Dependent on hypervisor status
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Versions of relevant libraries:
[pip3] flake8==6.1.0
[pip3] msgpack-numpy==0.4.8
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.3
[pip3] onnx==1.15.0
[pip3] pytorch-ignite==0.4.13
[pip3] pytorch-lightning==2.1.1
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchdata==0.6.0
[pip3] torchinfo==1.8.0
[pip3] torchmetrics==1.2.0
[pip3] torchtext==0.15.1
[pip3] torchvision==0.15.1
[conda] cudatoolkit 11.8.0 h4ba93d1_12 conda-forge
[conda] magma-cuda118 2.6.1 1 pytorch
[conda] mkl 2023.1.0 h213fc3f_46344
[conda] msgpack-numpy 0.4.8 pypi_0 pypi
[conda] numpy 1.26.1 pypi_0 pypi
[conda] pytorch-ignite 0.4.13 pypi_0 pypi
[conda] pytorch-lightning 2.1.1 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.1 pypi_0 pypi
[conda] torchdata 0.6.0 pypi_0 pypi
[conda] torchinfo 1.8.0 pypi_0 pypi
[conda] torchmetrics 1.2.0 pypi_0 pypi
[conda] torchtext 0.15.1 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi