I quantized a pre-trained FP32 model to INT8 by using PTQ in Pytorch, but when I print out the model parameters, they are not integer(INT8). Why? and how can I obtain the INT8 model?
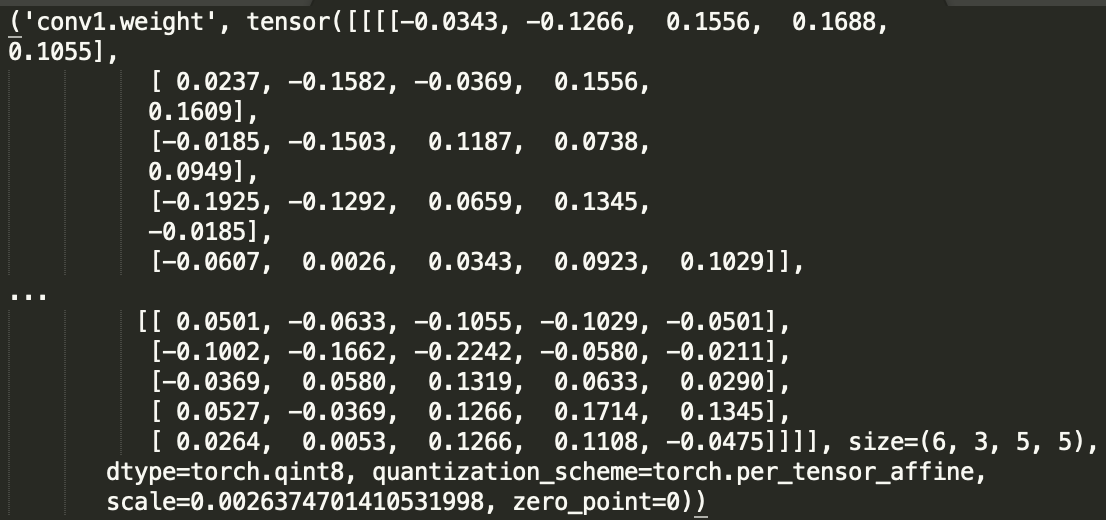
qtensor.int_repr() gives the integer weights but I think there might be a misunderstanding.
in general quantized tensors contain 3 components: int weights, scale and zero_points.
if your original tensor is something like: 0, .1, .2, .31
if you were to quantize it, you might get something with weight=[0,1,2,3] scale=.1, zero_point=0.
we aren’t actually quantizing the weights to integer values, for to be quantized tensor T we are trying to find s,z,T_int such that sT_int+z ~ T so what you are seeing is the actual values of sT_int+z (note: the actual quant/dequant equation depends)