I’ve discovered that issue when I was trying to understand why does my quantized version of EfficientNet-b4 work slower than the float one.
I use torch 1.6.0, fbgemm default config (torch.quantization.get_default_qconfig('fbgemm'))
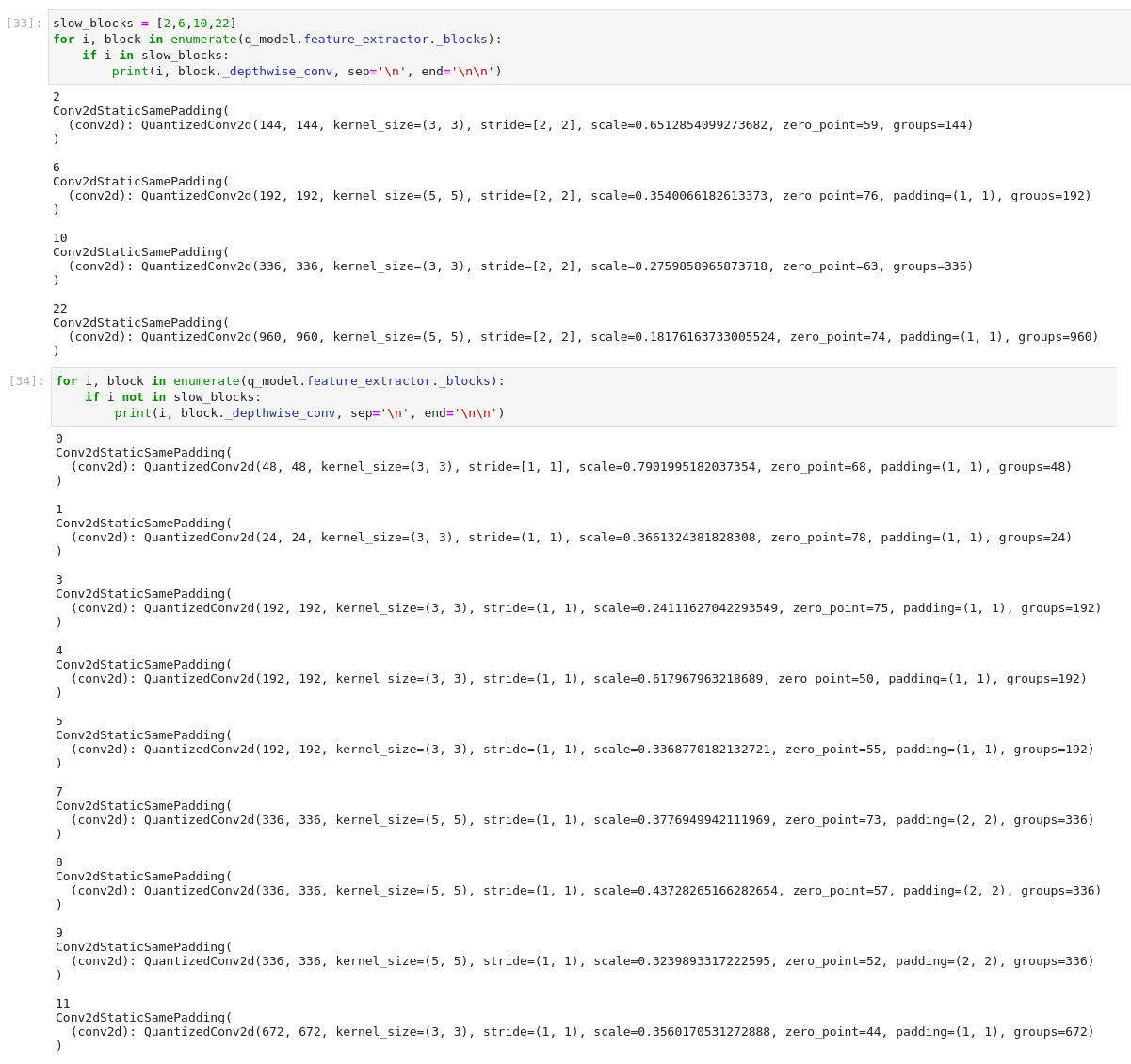
torchprof library shows that _depthwise_conv in blocks 2, 6, 10, 22 are the key problem: they are 3-10 times slower than in float model!
These layers differ from others only with (2, 2) stride instead of (1,1), (3,3), (5,5). I do not give the full list of hassle-free layers in the screenshot, but I’ve checked that
Is this the expected behavior? What could be the reason?
It works much better if you use equal padding for your 2, 6, 10 and 22 depthwise. For equal padding, depthwise conv goes through a fast path.
equal padding for (3, 3) kernel would be (1, 1) and (5, 5) it would be (2, 2). (Similar to the padding you have for (3, 3) and (5, 5) kernel sizes for other convolutions).
unfortunately, I do not understand what do you mean by saying “manually or through graph quantization”
If you mean, do I profile Torchscript model or original python one: I’ve done both, and both of them show bad performance. The layer-by-layer profiling via torchprof does not work with TorchScript models, but I expect that “slow” layers stay slow both in original model and in a Torchscript one, even if timing original model is not so precise
Quantization is done the same way as in MobileNet tutorial.
Here is the code snippet:
def try_config(qconfig, one_thread_inference=True, calibration_max_batches=None, metrics_max_batches=None):
# Fuse modules (my own implementation for EfficientNet; do you need it?)
q_model = fuse_modules()
# apply config (this looks complex because I do not quantize _conv_stem (1st convolution)
for block in q_model.feature_extractor._blocks:
block.qconfig = qconfig
q_model.quant = QuantStub(qconfig)
print(qconfig)
torch.quantization.prepare(q_model, inplace=True,
white_list=(
torch,nn.Conv2d,
torch.nn.BatchNorm2d,
torch.quantization.stubs.QuantStub,
torch.nn.quantized.modules.functional_modules.FloatFunctional
))
q_model.eval()
print('Post Training Quantization Prepare: Inserting Observers')
if one_thread_inference:
torch.set_num_threads(multiprocessing.cpu_count())
inference(q_model, dev_loader, max_batches=calibration_max_batches) # custom func just for model inference
print('Post Training Quantization: Calibration done')
# Convert to quantized model
torch.quantization.convert(q_model, inplace=True)
print('Post Training Quantization: Convert done')