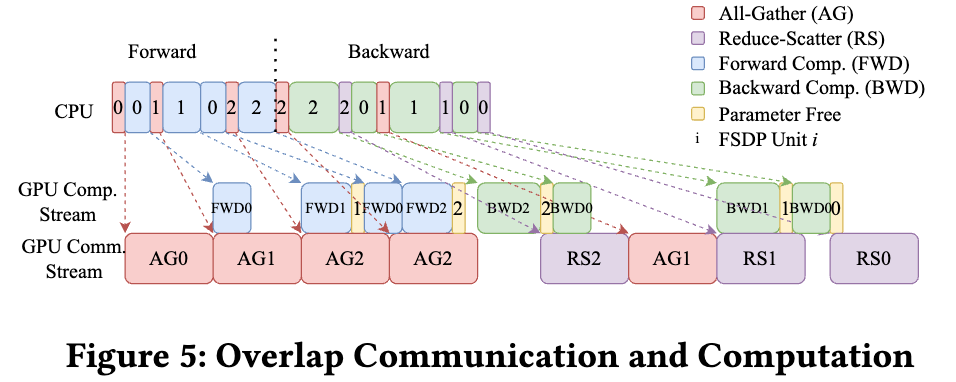
I have a question regarding Figure 5 in the PyTorch FSDP paper (Overlap Communication and Computation).
In the timeline, BWD1 and RS1 appear to start concurrently. My understanding is that Reduce-Scatter should only be triggered after the gradients for that FSDP unit are produced during the backward pass. This seems consistent with other units in the figure, such as BWD2 → RS2 and BWD0 → RS0, where RS clearly depends on the completion (or at least the gradient availability) of the corresponding backward computation.
Could you clarify why BWD1 and RS1 are shown as overlapping? Does RS1 begin as soon as partial gradients for that unit are ready (e.g., via gradient bucketing or chunking), or is there another scheduling mechanism involved that allows communication to overlap with the remaining backward computation?