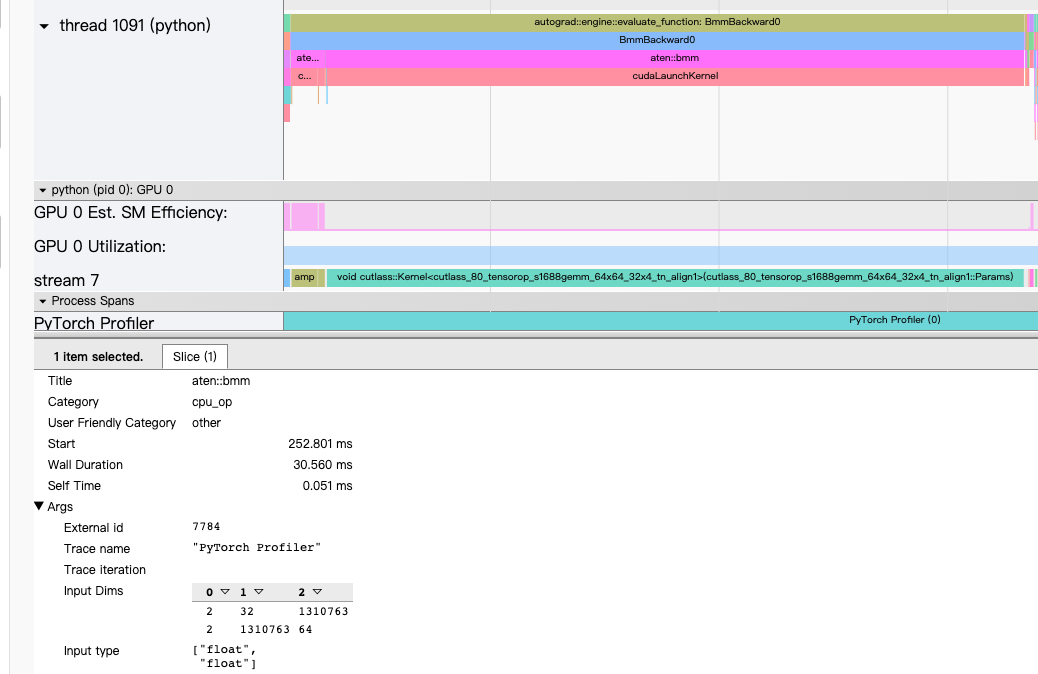
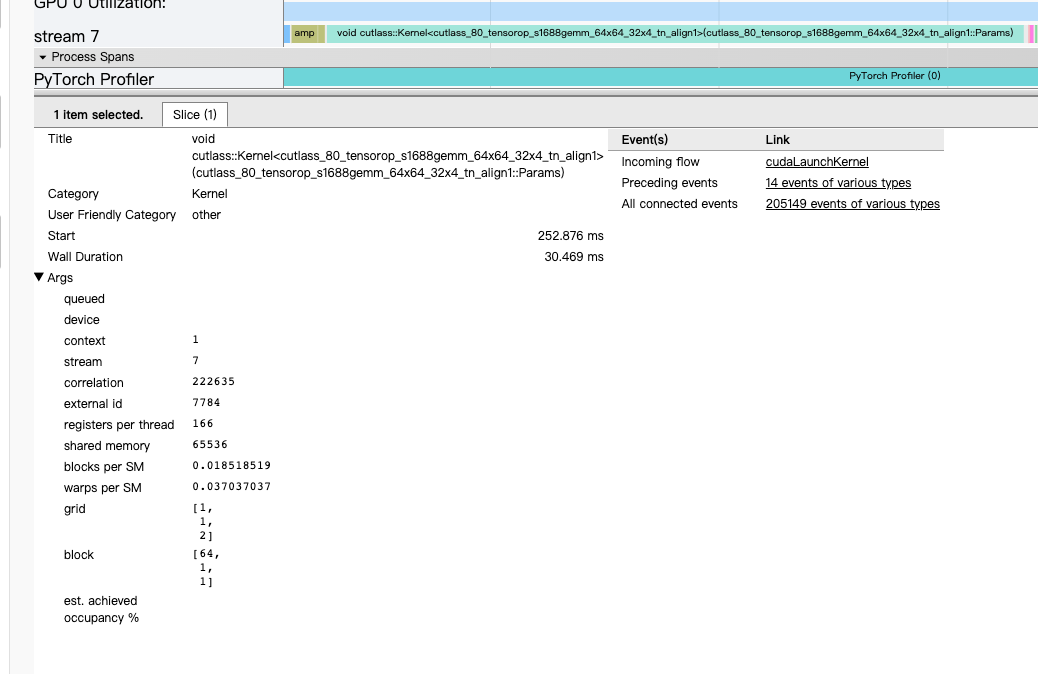
Here, I use torch profile on my model. and this is a part of results. Now I have a doubt: the bmmbackward’(aten::bmm)s input size is A(32, 1310763), and B(1310763, 64) but the uderlying cuda op(cutlass::Kernel<cutlass_80_tensorop_s1688gemm_64x64_32x4_tn_align1)‘s block size is(64,1,1) ,grid is (1,1,2). I think the number of input’ parameter should match the block * grid, but now there is a big gap between them. Meanwhile, it‘s time-consuming, this one op takes about 30ms.
I am not sure what you mean by “number of input parameter,” and how that should match kernel launch bounds without knowing the parallelization strategy used by the kernel. As a trivial example, if you include e.g., 1310763 as a factor in your parameter count, it wouldn’t make sense to increase the launch bounds according to this value as this dimension is reduced as part of the matmul.
If you think the achieved FLOPs is far below what is expected given your GPU, a script that reproduces this kernel call in PyTorch would be useful for debugging.