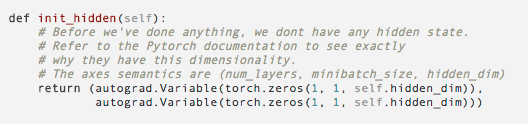
I read the tutorial about lstm. http://pytorch.org/tutorials/beginner/nlp/sequence_models_tutorial.html
I tried to use the cuda but failed. I do not know how to figure the bug.
Here is the code that I change.
model = LSTMTagger(EMBEDDING_DIM, HIDDEN_DIM, len(word_to_ix), len(tag_to_ix))
use_gpu=torch.cuda.is_available()
if(use_gpu):
model=model.cuda()
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# See what the scores are before training
# Note that element i,j of the output is the score for tag j for word i.
#print(tag_scores)
for epoch in range(10): # again, normally you would NOT do 300 epochs, it is toy data
#print(epoch,end=',')
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Also, we need to clear out the hidden state of the LSTM,
# detaching it from its history on the last instance.
model.hidden = model.init_hidden()
# Step 2. Get our inputs ready for the network, that is, turn them into
# Variables of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
if(use_gpu):
sentence_in=sentence_in.cuda()
targets = prepare_sequence(tags, tag_to_ix)
if(use_gpu):
targets=targets.cuda()
# Step 3. Run our forward pass.
tag_scores = model(sentence_in)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss = loss_function(tag_scores, targets)
loss.backward()
optimizer.step()
Traceback (most recent call last):
File "ner.py", line 169, in <module>
tag_scores = model(sentence_in)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 224, in __call__
result = self.forward(*input, **kwargs)
File "ner.py", line 121, in forward
lstm_out, self.hidden = self.lstm(embeds.view(len(sentence), 1, -1), self.hidden)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/module.py", line 224, in __call__
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/modules/rnn.py", line 162, in forward
output, hidden = func(input, self.all_weights, hx)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/_functions/rnn.py", line 351, in forward
return func(input, *fargs, **fkwargs)
File "/usr/local/lib/python3.5/dist-packages/torch/autograd/function.py", line 284, in _do_forward
flat_output = super(NestedIOFunction, self)._do_forward(*flat_input)
File "/usr/local/lib/python3.5/dist-packages/torch/autograd/function.py", line 306, in forward
result = self.forward_extended(*nested_tensors)
File "/usr/local/lib/python3.5/dist-packages/torch/nn/_functions/rnn.py", line 293, in forward_extended
cudnn.rnn.forward(self, input, hx, weight, output, hy)
File "/usr/local/lib/python3.5/dist-packages/torch/backends/cudnn/rnn.py", line 242, in forward
fn.hx_desc = cudnn.descriptor(hx)
File "/usr/local/lib/python3.5/dist-packages/torch/backends/cudnn/__init__.py", line 310, in descriptor
descriptor.set(tensor)
File "/usr/local/lib/python3.5/dist-packages/torch/backends/cudnn/__init__.py", line 116, in set
self, _typemap[tensor.type()], tensor.dim(),
KeyError: 'torch.FloatTensor'